Imagine a sudden, silent collapse of your primary payment gateway during a high-traffic flash sale. Customers face frozen checkout screens, support tickets skyrocket instantly, and the engineering team scrambles blindly across fragmented logs to locate the root cause. This chaotic bottleneck highlights the vulnerability of traditional infrastructure management and underscores the necessity of modern network optimization. Enterprises cannot afford reactive maintenance when managing complex, highly distributed systems.
Modern teams require systematic strategies to optimize network operations because infrastructure scale now expands exponentially. Manual intervention fails immediately when systems handle millions of simultaneous requests across multi-cloud environments. Network optimization transitions teams from firefighting unexpected outages to building self-healing, highly resilient software pipelines. This cultural and technical shift ensures that background infrastructure scales smoothly alongside expanding user demand.
This deep-dive architectural guide covers the foundational journey of infrastructure systems from industrial roots to automated workflows. We will explore structural operations management, the seven core principles of high-availability engineering, and critical metrics like error budgets. Additionally, this guide contrasts cultural philosophies with platform implementation, details real-world use cases, and outlines essential tools. Finally, you will find a clear professional roadmap to master these complex environments.
Mastering these systems requires deep structural knowledge and hands-on guidance from industry experts. You can explore complete technical blueprints and specialized operational paths at Noopsschool, which provides structured learning environments to help your engineering teams eliminate infrastructure bottlenecks completely.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise operations relied heavily on isolated, siloed departments where software developers and infrastructure administrators worked independently. Developers focused exclusively on shipping new features quickly, while operations teams prioritized maintaining system uptime at all costs. This fundamental misalignment created severe friction, as new code deployments frequently disrupted unstable production environments.
Whenever a system failed, teams wasted hours assigning blame rather than identifying structural weaknesses. Manual configurations dominated the deployment lifecycle, making environments highly inconsistent and prone to human error. Systems administrators spent their entire shifts manually provisioning servers, writing custom one-off scripts, and reacting to sudden alerts. This lack of standardized processes severely restricted corporate agility and blocked technological scaling.
Moving Toward Unified Workflow Automation
The introduction of shared operational methodologies transformed corporate infrastructure by breaking down institutional walls. Engineering organizations realized that stability and velocity must coexist rather than compete. By integrating software engineering practices directly into infrastructure management, teams began treating operations as a software problem.
This transition birthed unified workflow automation, where infrastructure configuration is managed through version-controlled code. Automated testing pipelines began validating environment changes before they reached production systems. Consequently, this shift drastically lowered deployment failures and minimized manual coordination. Teams stopped managing servers like fragile entities and started treating them as modular, automated components.
Global Expansion Across Commercial Ecosystems
As cloud computing matured, these integrated operational frameworks rapidly expanded across large-scale tech enterprises worldwide. High-growth digital platforms discovered that standard sysadmin methods could not sustain global microservice architectures. The need to maintain uniform performance across multiple geographical zones pushed automation to the forefront.
Today, global commercial ecosystems embed these efficiency principles into their core organizational structures. Tech giants, financial institutions, and retail platforms leverage automated infrastructure to handle massive traffic spikes seamlessly. These shared frameworks have evolved from an experimental tech philosophy into the standard operational blueprint for modern digital enterprises.
Defining Strategic Operations Management
The Core Operational Structure
Strategic operations management structures infrastructure as an interconnected ecosystem rather than a collection of separate servers. Information flows continuously from client endpoints through load balancers, application layers, and database clusters. Monitoring agents track this flow in real time, feeding performance telemetry into a centralized processing pipeline.
[User Request] ➔ [Load Balancer] ➔ [App Clusters] ➔ [Data Storage]
▲ │
└─────────── [Continuous Telemetry Feedback] ◄────┘
This structural architecture ensures that every component remains visible and accountable within the broader system. When a bottleneck develops in the storage layer, the telemetry system immediately alerts the traffic routing layer. This clear feedback loop allows the infrastructure to adjust dynamically, preserving baseline user experiences automatically.
Daily Tasks of Systems Coordinators
Systems coordinators execute complex software engineering tasks daily to maintain pipeline reliability. Instead of performing manual server patches, they write declarative code to automate routine infrastructure updates. They actively review system performance data to identify hidden latency trends before they trigger customer-facing incidents.
On any given day, these specialists configure telemetry dashboards, adjust auto-scaling thresholds, and participate in architectural reviews. They spend significant time writing automated scripts to eliminate repetitive maintenance tasks. When an incident occurs, they do not just fix the immediate bug; they engineer permanent platform guards.
Localized Control vs. Broad System Architecture
Managing modern infrastructure requires balancing granular component tracking with broad system architecture control. Localized control focuses on specific performance metrics, such as a single database container’s CPU utilization. While this micro-level visibility matters, optimizing individual pieces in isolation can sometimes introduce unexpected systemic imbalances.
Broad system architecture management looks at the entire multi-system infrastructure holistically. It traces end-to-end user journeys across dozens of interconnected microservices to ensure smooth delivery. Engineers must understand how a configuration change in a localized caching layer ripples through the entire global network.
The Efficiency Mindset
The transition to high-efficiency operations demands a deep cultural shift that prioritizes long-term system stability over short-term fixes. Teams operating with this mindset reject temporary workarounds that merely disguise underlying infrastructure flaws. They view every operational failure as an architectural gap that requires an automated, engineered solution.
This mindset values visibility, predictable deployments, and proactive risk management above all else. Engineers systematically design systems to fail safely without causing total, cascading network outages. This continuous focus on engineering resilience ultimately builds businesses that adapt to volatile market demands effortlessly.
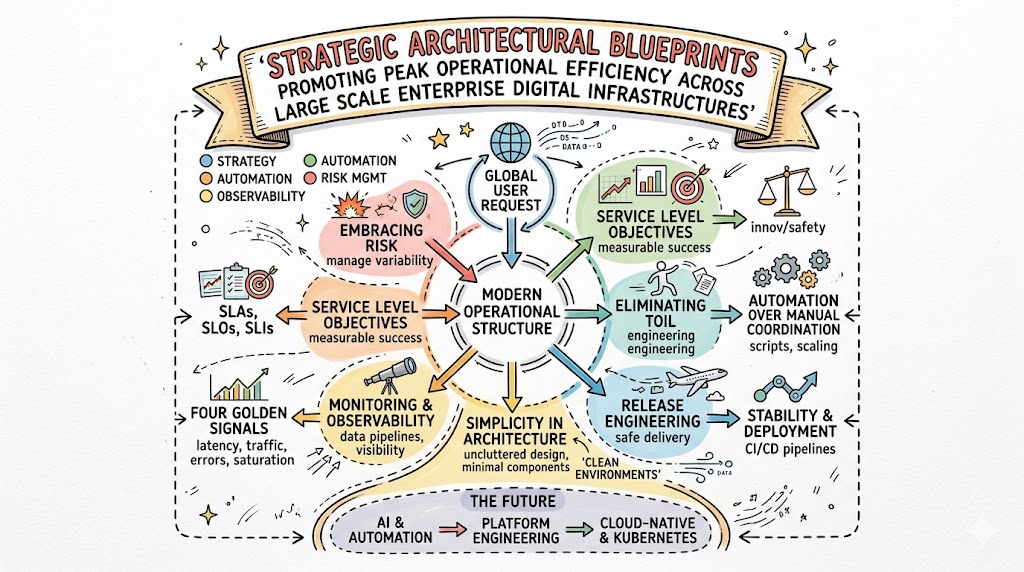
The 7 Core Principles of Network Optimization
1. Embracing Risk and Managing Variability
Modern operations accept that software systems are inherently imperfect and that achieving absolute 100% uptime is mathematically impossible. Trying to reach perfect reliability costs a prohibitive amount of money and slows feature development to a crawl. Therefore, engineering teams focus on defining and managing an acceptable level of systemic risk instead.
By acknowledging that components will fail eventually, teams build robust fault-tolerant architectures that insulate users from underlying disruptions. They use statistical models to balance rapid code deployment with baseline system safety. This pragmatic approach removes the fear of failure, allowing organizations to innovate confidently while protecting core operations.
2. Establishing Service Level Objectives (SLOs)
Systems require objective, quantifiable targets to measure operational success accurately. Teams establish clear Service Level Objectives that define the precise performance boundaries required to keep customers happy. These targets prevent organizations from making arbitrary decisions about system health during high-pressure situations.
[Raw System Telemetry] ➔ [Service Level Indicators] ➔ [Service Level Objectives]
SLOs align development priorities with operational realities by grounding engineering discussions in hard user data. If a system stays comfortably within its objective boundaries, developers can safely push experimental features. Conversely, if an objective faces breaches, teams pivot resources to harden infrastructure stability.
3. Eliminating Toil and Manual Processes
Toil represents repetitive, manual tasks that scale linearly with infrastructure size and lack long-term strategic value. Examples include manually resetting stuck application servers, creating user accounts by hand, or running manual database backups. Left unchecked, toil drains engineering energy and introduces frequent human mistakes into production environments.
High-performing teams continuously track operational tasks to identify manual burdens and engineer them away through automation. When an engineer automates a tedious manual process, they free up valuable hours for complex architectural design. Eliminating toil ensures that the operations team can manage thousands of new servers without increasing headcount.
4. Monitoring & Observability Across the Pipeline
Comprehensive visibility across the entire deployment pipeline prevents dangerous blind spots from hiding deep within infrastructure layers. Modern observability goes far beyond simple ping checks that merely confirm whether a server is online or offline. It gathers rich telemetry across logs, distributed traces, and system metrics to provide full structural context.
┌──► Metrics (Numerical trends over time)
│
Observability ──┼──► Logs (Granular point-in-time events)
│
└──► Traces (End-to-end request pathways)
This deep insight allows operators to trace the exact journey of a single slow request across multiple microservices. Teams detect subtle performance drops, memory leaks, and network anomalies before they impact end users. True observability changes infrastructure management from guessing what went wrong to knowing exactly where to fix it.
5. Automation Over Manual Coordination
Scaling modern enterprise workflows requires an engineering approach that replaces manual coordination with smart software solutions. Relying on human checklists or manual approvals to deploy software creates severe organizational bottlenecks. High-efficiency operations leverage self-triggering pipelines to manage system changes safely.
Automated systems provision cloud resources, run regression tests, and execute rolling updates without human intervention. If a new code module causes an unexpected error, the automated system immediately rolls back the deployment. This programmatic scaling eliminates human lag, ensuring consistent performance throughout complex cloud networks.
6. Release Engineering and Deployment Stability
Release engineering focuses on the safe, predictable, and repeatable delivery of application and infrastructure updates. Teams utilize advanced strategies like canary deployments to introduce changes to a tiny fraction of live users first. This isolation limits the blast radius of unexpected bugs, shielding the broader customer base from disruption.
[New Code Build] ➔ [Canary Group: 2% Users] ➔ [Verify Health] ➔ [Global Rollout: 100%]
Engineers treat deployment pipelines as core software products that require continuous testing and refinement. Version control tracks every single infrastructure adjustment, allowing teams to audit changes or revert states instantly. This rigorous discipline turns risky software releases into non-event, everyday operational tasks.
7. Simplicity in Network Architecture
Complex network environments directly increase failure surfaces, making troubleshooting incredibly difficult during live outages. Unnecessary layers, redundant components, and overly complicated routing rules create hidden failure modes that trip up teams. High-efficiency operations aggressively champion clean, minimal architectural designs.
Engineers focus on decoupling system components so that individual failures cannot trigger catastrophic cascading reactions. They document every data path clearly and remove legacy configurations that no longer serve business needs. Keeping things simple ensures that infrastructure remains easy to understand, easy to maintain, and easy to secure.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Organizations must understand the clear differences between Service Level Agreements, Service Level Objectives, and Service Level Indicators to track reliability effectively.
- Service Level Agreement (SLA): A formal business contract between a service provider and an external customer detailing promised performance, uptime, and financial penalties for failures.
- Service Level Objective (SLO): A target reliability metric defined internally by engineering teams to ensure the system satisfies the external agreement comfortably.
- Service Level Indicator (SLI): A precise, quantitative measurement of real-time performance, such as request latency or error rate, that indicates compliance with the objective.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the total acceptable amount of system unreliability permitted over a specific timeframe, such as a month. Calculated mathematically as $1 – \text{SLO}$, this concept acts as a dynamic buffer that balances structural innovation with baseline safety. For example, a system with a 99.9% uptime objective possesses a 0.1% monthly error budget.
$$Error\ Budget = 100\% – SLO\%$$
When the error budget remains full and healthy, product teams can aggressively ship innovative, higher-risk features to market. However, if unexpected outages consume the budget entirely, a strict policy freezes new feature releases immediately. The entire engineering organization then shifts focus exclusively to fixing infrastructure bugs and improving system resilience.
Toil — The Silent Productivity Killer in Infrastructure
Toil acts as a silent productivity killer because it consumes valuable engineering hours without improving system architecture. Teams must actively measure their operational workloads to differentiate between creative engineering work and repetitive manual toil. If a task is administrative, repetitive, and automatable, it qualifies as toil.
Organizations calculate their total toil overhead by tracking the percentage of time engineers spend on reactive tickets. High-efficiency operations set strict structural boundaries, ensuring that toil never consumes more than 50% of an engineer’s schedule. The remaining time must always be dedicated to proactive engineering work that permanently eliminates operational friction.
Incident Management & Postmortems
When unexpected outages inevitably strike, structured incident management frameworks guide teams to restore services quickly and calmly. Clear operational roles separate communication leads from technical investigators, preventing chaotic duplication of troubleshooting efforts. Once the system returns to a healthy state, the team initiates a blameless postmortem process.
[Detect Outage] ➔ [Assign Roles] ➔ [Mitigate Issue] ➔ [Blameless Postmortem]
Blameless cultures assume that engineers act with good intentions based on the information available to them at the time. Postmortems analyze the systemic flaws, missing alerts, and architectural weaknesses that permitted the human error to occur. This open approach turns every single production failure into a valuable learning lesson that hardens future infrastructure.
Capacity Planning
Capacity planning ensures that enterprise infrastructure scales efficiently ahead of organic user growth and sudden demand spikes. Teams analyze long-term historical telemetry trends to forecast when computing resources will approach saturation boundaries. This practice prevents costly over-provisioning while ensuring the network never drops packets during peak events.
Modern capacity planning combines historical forecasting with regular load testing to validate infrastructure limits under stress. Engineers simulate extreme traffic scenarios in isolated testing environments to discover hidden network breakpoints. This proactive preparation allows teams to purchase resources or adjust scaling rules long before users experience performance slowdowns.
The Four Golden Signals of Pipeline Performance
To maintain a healthy, optimized network infrastructure, teams must continuously track the four golden signals of performance.
| Metric | Definition | Primary Monitoring Focus |
| Latency | The time taken to service a request. | Tracking the speed difference between successful and failed requests. |
| Traffic | The demand placed on the system. | Measuring network requests per second, bandwidth usage, or concurrent sessions. |
| Errors | The rate of requests that fail. | Isolating explicit 500-level codes, implicit failures, and policy drops. |
| Saturation | The fullness of system resources. | Pinpointing memory, CPU, and disk constraints before bottlenecks occur. |
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many organizations mistake adopting automated cloud platforms for undergoing a genuine operational culture transformation. Platform implementation focuses entirely on deploying modern infrastructure tools, writing automated scripts, and configuring advanced cloud environments. While these technical assets are highly valuable, tools alone cannot solve deep-seated organizational friction.
The cultural philosophy defines how teams collaborate, approach risk, learn from failures, and value system stability. A healthy culture encourages transparency, values blameless learning, and actively rewards long-term engineering fixes over superficial workarounds. Without this underlying cultural shift, teams simply use modern tools to execute old, inefficient operational habits.
Roles & Responsibilities Compared
While both areas focus on system optimization, their daily engineering duties differ significantly across the lifecycle.
- Platform Engineers: Focus on building internal developer platforms, maintaining CI/CD systems, and provisioning shared infrastructure components.
- Site Reliability Engineers: Focus on application uptime, monitoring system health, managing error budgets, and conducting blameless postmortems.
- Systems Architects: Focus on long-term structural design, high-level network topology, and security guardrails.
- Infrastructure Teams: Focus on hardware lifecycle management, core networking protocols, and baseline operating system tuning.
Can You Have Both Disciplines?
Modern enterprises can absolutely cultivate both robust technical implementations and healthy operational cultures simultaneously. In fact, these two disciplines complement each other perfectly within high-velocity engineering organizations. The platform engineering team builds the scalable foundations, while the reliability culture guides how teams utilize those frameworks.
When culture and implementation align, developers leverage self-service tools to deploy code safely within pre-engineered reliability boundaries. Software engineers take ownership of their application performance because the culture removes the fear of blame. This harmony allows organizations to ship features quickly without sacrificing baseline network stability.
Which One Should Your Team Adopt?
Choosing where to focus your engineering resources depends entirely on your current organizational size and structural maturity. Small startups with minimal headcounts should prioritize building a strong reliability culture before buying complex platform tools. Instilling a mindset of automation and blameless learning early prevents the accumulation of massive operational debt.
[Small Startup] ➔ Focus first on: [Reliability Culture & Simple Tools]
[Large Company] ➔ Focus next on: [Platform Engineering & Custom Internal Portals]
Larger enterprises managing hundreds of distributed microservices must invest heavily in dedicated platform engineering initiatives. These organizations require centralized automation portals to eliminate duplicate efforts across fragmented development teams. Ultimately, scaling businesses must blend both disciplines to maintain market agility while safeguarding system performance.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Leading software enterprises track granular operational metrics to keep their global digital systems running smoothly. They monitor real-time user traffic trends to route workloads dynamically around congested regional data centers. By analyzing telemetry data continuously, these organizations catch minor performance regressions before they spread across the network.
These tech leaders link their infrastructure metrics directly to business outcomes to justify future engineering investments. For example, they trace how a 50-millisecond reduction in database latency directly improves digital checkout completion rates. This data-driven approach elevates infrastructure management from an opaque cost center to a clear business driver.
Chaos Engineering Approaches to Resilient Systems
Top-tier engineering teams do not wait around for random hardware failures to test their infrastructure resilience. Instead, they use chaos engineering practices to inject controlled disruptions into live production environments intentionally. They automatically terminate random server instances or introduce network lag to observe how the broader system responds.
These controlled experiments validate whether auto-scaling groups and self-healing systems react correctly under real-world pressure. If a system fails during a planned chaos test, engineers fix the architectural gap during standard working hours. This proactive disruption ensures that unexpected real-world infrastructure failures become boring, non-disruptive events.
Handling Reliability at Massive Scale
Global digital platforms manage millions of concurrent user transactions safely by utilizing decoupled, highly distributed microservice architectures. They break down monolithic software applications into isolated services that communicate via lightweight network protocols. This isolation ensures that an unexpected crash in a comment module cannot bring down the primary payment engine.
These massive systems implement advanced traffic management patterns like circuit breakers and rate limiters at every boundary. If a specific service becomes overwhelmed with requests, the circuit breaker opens to shed load and protect the database. This programmatic resilience allows large enterprises to maintain baseline availability even during unprecedented traffic surges.
High-Availability in Fintech Operations
Financial technology platforms operate within zero-tolerance environments where even a few seconds of network downtime causes massive revenue losses. They implement rigorous multi-region active-active architectures to ensure transactional continuity across their entire system. Every financial event writes to multiple geographically separated databases simultaneously using strict consensus algorithms.
Fintech operations teams back these redundant networks with aggressive monitoring alerts that fire the instant anomaly boundaries are crossed. They automate compliance checks and security scanning directly within their delivery pipelines to preserve data integrity. This absolute focus on security and availability protects consumer capital and maintains strict regulatory compliance.
Scaled-Down but Essential Systems for Startups
Early-stage startups can apply these core efficiency principles efficiently without drowning in complex enterprise infrastructure overhead. Instead of building massive custom platform utilities, they leverage managed cloud services and lightweight open-source monitoring tools. They focus their limited engineering energy on automating their core deployment loops and tracking basic golden signals.
By establishing simple SLOs early, a lean startup can protect its engineers from severe operational burnout. They automate routine code deployment and infrastructure provisioning to ensure their tiny team remains focused on product innovation. This early investment in basic operational hygiene creates a strong foundation that supports rapid corporate growth.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
Many companies mistakenly assume they have built a modern reliability practice simply because they put engineers on an on-call rotation. True efficiency engineering involves writing proactive software code to optimize networks, not just waking up engineers at midnight to manual alerts. Passing repetitive manual fixes off as an operational strategy burns out talent and leaves root vulnerabilities completely unaddressed.
Mistake 2 — Setting Unrealistic SLOs
Product managers often demand absolute perfect 100% uptime without understanding the immense engineering costs involved. Demanding unrealistic objectives stalls software feature development entirely, as the engineering team spends all their time chasing impossible stability targets. Smart teams set realistic objectives based on actual user satisfaction, reserving budget for rapid innovation.
Mistake 3 — Ignoring Toil Until It’s Too Late
Organizations accumulate severe operational debt when they allow manual, repetitive support tasks to pile up unchecked. When engineers spend their entire week addressing routine system tickets, they have zero time left to build automated platform guardrails. This neglect creates a dangerous loop where infrastructure growth requires a linear, unsustainable increase in engineering headcount.
Mistake 4 — Skipping Blameless Postmortems
Punishing or blaming engineers for accidental production mistakes creates a toxic corporate culture of fear and secrecy. When teams fear retribution, they hide operational errors, cover up close calls, and avoid investigating complex system failures. Skipping blameless reviews prevents organizations from identifying the deep systemic flaws that allowed the accident to occur.
Mistake 5 — Monitoring Without Actionable Alerts
Configuring telemetry systems to fire alerts for every single minor fluctuation triggers severe alert fatigue across engineering teams. When on-call engineers receive hundreds of non-actionable notifications daily, they naturally begin ignoring all incoming pages. Every alert must point directly to a real, urgent problem that requires immediate human intervention to prevent user disruption.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Excluding operational engineers from initial software architecture discussions often leads to the deployment of unscalable applications. Software developers frequently design complex features that perform beautifully on a local laptop but collapse under real production workloads. Operational input must guide system design from day one to ensure long-term maintainability, security, and scaling efficiency.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Enterprise teams leverage specialized telemetry suites to maintain deep visibility across their entire multi-cloud network infrastructure. Prometheus serves as a powerful open-source time-series database designed to collect and store detailed numerical system metrics. Teams seamlessly pair this metrics collection engine with Grafana to generate real-time, interactive performance visualization dashboards.
For complex, distributed enterprise environments, platforms like Datadog and New Relic provide comprehensive, end-to-end full-stack observability. These advanced tools correlate system infrastructure logs, metrics, and microservice traces within a single unified dashboard. This deep integration allows engineering teams to trace performance issues from high-level user actions down to specific database queries.
Incident Management
When critical production systems suffer unexpected outages, organizations use dedicated coordination platforms to organize their responses. PagerDuty acts as a smart routing hub, ingest alerts from monitoring tools and dispatching pages to the correct on-call engineer. This automated routing prevents valuable mitigation minutes from being wasted during high-pressure infrastructure incidents.
These orchestration platforms integrate directly with team communication channels to create centralized incident command centers automatically. They document every timeline event, status change, and internal chat log throughout the lifecycle of the technical outage. This comprehensive data capture streamlines the incident resolution path and provides clear data for subsequent postmortem reviews.
CI/CD & Release Engineering
Modern release engineering practices rely on automated delivery pipelines to test, validate, and deploy infrastructure updates smoothly. Jenkins remains a widely adopted automation engine used to execute custom build configurations and run automated regression suites. This reliable framework ensures that all new code branches satisfy baseline engineering requirements before approaching production networks.
[Code Check-in] ➔ [Jenkins Build & Test] ➔ [Argo CD GitOps Git Sync] ➔ [Production Rollout]
For cloud-native Kubernetes environments, teams leverage Spinnaker and Argo CD to manage advanced GitOps deployment workflows. Argo CD continuously monitors version-controlled repositories and automatically synchronizes the live cluster state with the declared configuration files. This programmatic automation completely eliminates human configuration errors, ensuring uniform performance across all cloud regions.
Chaos Engineering
To uncover hidden infrastructure vulnerabilities before they trigger real-world customer outages, teams deploy automated failure injection tools. Chaos Monkey, originally pioneered by digital streaming enterprises, randomly terminates live virtual machine instances within production environments. This continuous, controlled disruption forces software architectures to handle infrastructure loss gracefully without dropping active user sessions.
Modern chaos frameworks allow engineers to simulate complex network degradation scenarios, such as regional latency drops or database blackouts. Injecting these controlled failures validates whether auto-scaling systems and circuit breakers respond correctly under pressure. This proactive testing changes engineering cultures from hoping for stability to knowing the system is resilient.
SLO Management
Tracking reliability compliance against strict internal targets requires dedicated metrics tracking infrastructure. Nobl9 specializes in ingesting raw performance data from various monitoring sources and calculating error budget consumption rates in real time. This focused visualization provides product managers and engineering leaders with clear data regarding system safety boundaries.
These tracking platforms alert development teams long before a slow performance trend completely breaches an agreed service objective. Grounding engineering choices in real-time reliability data helps organizations avoid arbitrary arguments regarding code deployment speed. SLO management tools provide the objective frameworks needed to balance rapid software innovation with infrastructure safety.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Aspiring operations experts must master foundational Linux terminal commands and understand core operating system internals deeply. You need to navigate file systems, analyze network sockets, manage permissions, and troubleshoot process trees confidently using command-line utilities. Proficiency in scripting languages like Python or Go is essential to automate routine maintenance and build custom platform tools.
Additionally, specialists must possess a thorough understanding of core networking protocols, including TCP/IP routing, DNS resolution, and load balancing. You need to know how data moves across cloud networks and understand how to secure those pathways using firewalls. Mastering these fundamental concepts allows engineers to diagnose complex infrastructure failures that confound superficial software developers.
The Professional Learning Path
The journey to infrastructure mastery begins by managing single-server environments and learning the basics of version control with Git. Once you master manual setups, transition immediately to learning infrastructure-as-code principles using automation utilities like Terraform. This phase teaches you how to declare cloud resources programmatically, ensuring your environments remain fully repeatable.
Next, expand your engineering scope by learning containerization concepts with Docker and orchestration frameworks like Kubernetes. Learn how to configure continuous integration pipelines, establish service objectives, and build comprehensive telemetry dashboards. Advanced seniors focus on mastering global multi-cloud topology, financial cost optimization, and designing self-healing system architectures.
[1. Linux & Git Basics] ➔ [2. Infrastructure as Code] ➔ [3. Kubernetes & CI/CD] ➔ [4. Enterprise Architecture]
Certifications Worth Pursuing
Industry-recognized professional certifications validate your technical infrastructure expertise and accelerate your career progression within competitive global markets. Earning credentials like the Certified Kubernetes Administrator (CKA) demonstrates your practical ability to manage complex container clusters under real pressure. Cloud-specific architectural credentials from providers like AWS, Google Cloud, or Microsoft Azure further verify your distributed systems engineering design skills.
Focus on pursuing certifications that require hands-on, practical lab examinations rather than simple multiple-choice question tests. These rigorous practical challenges prove to prospective employers that you can actually solve live infrastructure problems calmly. Combining these respected technical credentials with real-world engineering experience makes you a highly sought-after professional in the technology sector.
Educational Resources with Noopsschool
Acquiring these advanced operational skills requires access to high-quality, structured learning materials designed by veteran infrastructure engineers. Exploring the technical courses and interactive blueprints provided by Noopsschool accelerates your educational journey by replacing abstract theory with practical labs. Their educational platform focuses heavily on real-world scenarios, teaching you how to build resilient pipelines from scratch.
Noopsschool offers deep dives into advanced monitoring setups, GitOps workflows, Kubernetes management, and enterprise automation strategies. Their mentor-guided curriculum ensures you avoid common architectural traps and master the tools driving modern digital platforms. Investing your time in these structured educational paths prepares your engineering teams to manage massive infrastructure scaling confidently.
The Future of Systems Management
AI and Automation in System Optimization
Machine learning models are rapidly transforming modern infrastructure management by analyzing massive streams of real-time telemetry data. These intelligent systems locate subtle performance anomalies and predict hardware failures long before they trigger customer-facing outages. AI-driven insights drastically accelerate root cause analysis by automatically connecting disparate logs, traces, and infrastructure metrics.
As these automated systems mature, they will transition from providing passive advisory alerts to executing real-time autonomous remediation. An intelligent network controller can detect a localized traffic surge, provision additional cloud nodes, and adjust routing tables automatically. This programmatic speed minimizes human intervention, ensuring optimal system performance throughout volatile demand spikes.
Platform Engineering — The Evolution of Infrastructure
Platform engineering represents a major evolutionary step in infrastructure management, focusing on optimizing the internal developer experience. Instead of forcing software developers to navigate raw cloud APIs, dedicated platform teams build unified internal developer portals. These self-service portals encapsulate complex infrastructure, security policies, and deployment rules into clean, simple templates.
[Developer] ➔ [Self-Service Internal Portal] ➔ [Automated Secure Infrastructure Delivery]
This structural shift allows application developers to provision databases, spin up environments, and launch pipelines safely with a single click. Platform engineering eliminates organizational friction by building secure, pre-engineered guardrails directly into the corporate ecosystem. This automation helps enterprises maintain strict compliance and reliability standards while increasing software delivery speeds.
Management in Cloud-Native & Kubernetes Environments
The widespread adoption of dynamic, containerized application clusters introduces unique infrastructure orchestration challenges that demand modern management strategies. Kubernetes networks are highly ephemeral, with container instances continuously launching, scaling, and terminating across distributed cloud hardware. Maintaining visible, secure data paths within these rapidly changing environments requires advanced service mesh architectures.
Operations teams must manage configuration states programmatically using automated declarative pipelines and strict GitOps workflows. They implement advanced container security frameworks and resource allocation policies to prevent localized resource starvation. Mastering these cloud-native orchestration methodologies ensures that large-scale enterprise environments remain highly flexible, scalable, and resilient against hardware disruptions.
Operational Skills That Will Matter Most
As infrastructure systems grow more abstract, the core skill sets required by top-tier operations experts must evolve accordingly. Engineers must look past simple server maintenance and focus heavily on data engineering, distributed systems architecture, and deep observability. The ability to write complex code that manages other software systems is becoming a mandatory prerequisite for modern careers.
Furthermore, financial cost optimization—often termed FinOps—is rapidly becoming a critical priority for expanding digital enterprises. Engineers must know how to design high-performance architectures that maximize computing efficiency while minimizing unnecessary cloud waste. Blending technical engineering expertise with sharp financial awareness ensures that infrastructure scaling remains sustainable for the business over the long term.
FAQ Section
- What is the typical career path for a network operations or site reliability expert?Professionals usually begin their careers as junior systems administrators, tech support engineers, or junior software developers. As they master automation, scripting, and cloud infrastructure, they transition into dedicated reliability or platform engineering roles. Senior specialists eventually progress into enterprise systems architects or principal infrastructure infrastructure directors, steering long-term technology roadmaps.
- How does this discipline differ from traditional IT operations or systems administration?Traditional systems administration relies heavily on manual configurations, reactive troubleshooting, and human checklists to maintain isolated servers. Modern operations treat infrastructure as a software problem, leveraging automated code pipelines to manage entire multi-cloud networks. This programmatic approach replaces manual maintenance with self-healing, scalable code architectures that eliminate repetitive toil.
- What are the average salary trends for infrastructure optimization specialists globally?Due to the critical shortage of talent capable of managing massive cloud networks, compensation trends remain exceptionally high. Mid-level reliability and platform engineers frequently earn between $120,000 and $160,000 annually in major technology markets. Senior architects and principal staff specialists regularly secure total compensation packages exceeding $200,000, reflecting their immense business value.
- Can you explain the practical difference between an SLO and an SLA in simple terms?An SLA is a formal legal contract that promises specific system uptime to external customers and defines financial penalties for failures. An SLO is an ambitious internal performance target used by engineering teams to measure infrastructure health day-to-day. The internal objective is always set strictly higher than the external agreement to provide a safe operational buffer.
- Which scripting languages are most important for automating modern enterprise networks?Python remains an industry standard due to its readability, massive library ecosystem, and widespread support across cloud automation platforms. Go has also become incredibly critical, as major cloud-native infrastructure technologies like Docker and Kubernetes are built entirely on it. Mastering these two languages allows engineers to interact efficiently with modern APIs and build high-performance tools.
- How do error budgets help product developers and operations teams collaborate better?Error budgets remove arbitrary political friction by providing a shared, data-driven framework for managing operational risk. When the error budget is full, product developers have the clear authority to deploy innovative, high-risk features rapidly. If the budget drains, the data automatically triggers a feature freeze, shifting all resources to improving system stability.
Final Summary
Optimizing modern network operations requires a systematic commitment to automation, clear service level objectives, and a healthy blameless engineering culture. Embracing data-driven frameworks like error budgets allows organizations to balance rapid software innovation with stable, high-availability infrastructure performance. Eliminating manual toil and embedding deep observability across your delivery pipelines permanently removes systemic bottlenecks. Ultimately, maintaining a clean, simple, and automated network architecture ensures your enterprise infrastructure scales effortlessly alongside expanding market demands.
Building these resilient, self-healing platforms requires continuous learning and a strong mastery of modern cloud-native technologies. You can empower your engineering teams with the advanced technical skills and operational frameworks needed for this transformation by exploring the specialized training tracks at Noopsschool.