Imagine an enterprise network crashing during a peak traffic surge due to a single mistyped configuration command. This single manual error disrupts thousands of active customer transactions, creating immediate operational bottlenecks and stalling business revenue. Traditional manual interventions simply cannot keep pace with the massive scale of modern interconnected systems.
The Impact of Automation on Network Operations represents the systematic shift from manual device configuration to software-driven, programmatic control of network resources. Modern teams need this approach because software-defined workflows allow systems to scale seamlessly, reduce human errors, and handle rapid traffic fluctuations automatically. This comprehensive guide covers the evolution of network management, foundational automated principles, essential operational metrics, and practical deployment tools. To master these modern techniques and eliminate manual configuration bottlenecks, discover the expert-led educational paths available at Noopsschool.
Detailed Breakdown of Network Automation
Network automation utilizes programmable software scripts, APIs, and policy-driven architectures to manage physical and virtual network devices. Instead of logging into individual routers and switches via a Command Line Interface (CLI), engineers deploy centralized code to orchestrate changes across thousands of devices simultaneously.
This operational shift replaces static network layouts with dynamic, self-healing infrastructures. Programmatic routing, automated load balancing, and immediate security policy updates allow infrastructure to respond dynamically to application demands. Consequently, organizations eliminate provisioning delays, ensure uniform compliance across all environments, and optimize hardware utilization.
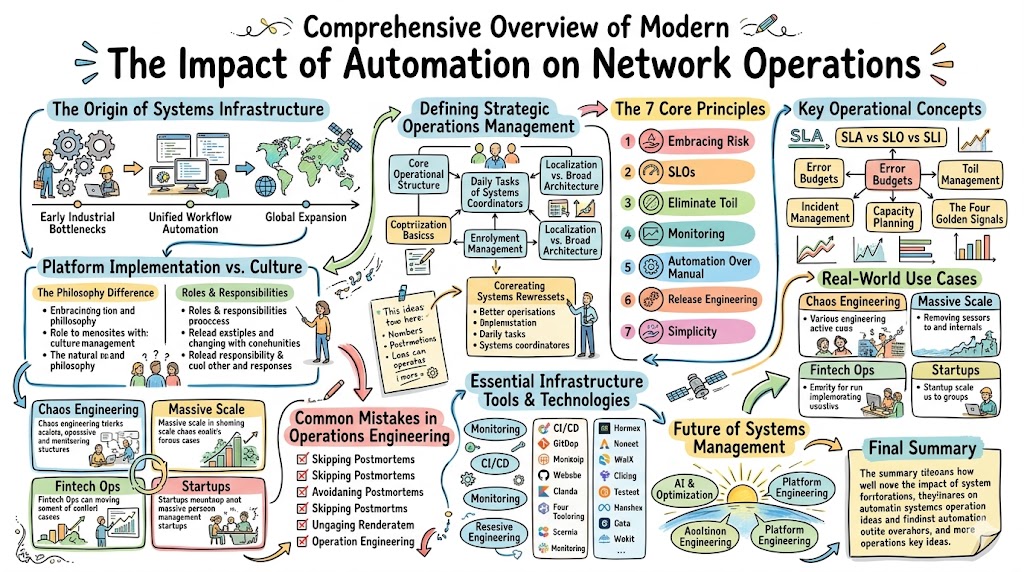
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise operations relied heavily on fragmented, manual hardware provisioning processes. Administrators spent long hours configuring individual servers, switches, and storage arrays using static text templates.
Siloed engineering groups worked in complete isolation, creating huge operational disconnects between software developers and network administrators. This division caused frequent deployment delays, as network teams struggled to validate manual configurations against rapidly changing software requirements.
Moving Toward Unified Workflow Automation
As application architectures moved toward distributed computing, manual provisioning methods became a major operational bottleneck. Organizations began adopting unified workflow automation to break down traditional operational silos.
By treating infrastructure configurations as programmatic code, teams created shared repositories for network templates and system scripts. This unified strategy allowed network specialists and software developers to collaborate effectively on automated pipelines, ensuring faster, more predictable system deployments.
Global Expansion Across Commercial Ecosystems
Automated frameworks quickly expanded across large-scale commercial tech enterprises and hyperscale data centers. Global service providers realized that manual network engineering could not support millions of concurrent web applications.
These massive enterprises pioneered software-defined networking models to manage worldwide digital footprints dynamically. Today, this software-driven architecture forms the backbone of modern global e-commerce, streaming media networks, and distributed banking platforms.
Defining Strategic Operations Management
The Core Operational Structure
Strategic operations management centers on a structured pipeline where system telemetry informs automated control loops. Network devices constantly stream real-time performance data to a centralized analytics engine.
+-------------------+ Telemetry Data +--------------------+
| Network Devices | -----------------------> | Centralized Engine |
| (Switches/Routers)| <----------------------- | (Telemetry/APIs) |
+-------------------+ Automated Updates +--------------------+
The system processes this telemetry data to evaluate overall network health against preconfigured operational templates. When the analytics engine detects a bottleneck or a performance drop, it triggers automated API calls to adjust configurations across the entire infrastructure.
Daily Tasks of Systems Coordinators
Systems coordinators spend their days designing, testing, and refining programmatic deployment scripts rather than running manual troubleshooting commands. They build automated playbooks to handle routine tasks like software updates, security patching, and device provisioning.
Additionally, these specialists audit continuous integration pipelines to guarantee that new configuration code adheres to strict corporate compliance metrics. They also build robust data visualization dashboards to monitor automated system responses to network anomalies.
Localized Control vs. Broad System Architecture
Managing modern environments requires a deep understanding of both local configurations and broad system architectures. Localized control focuses on specific performance metrics, such as fine-tuning interface queues on a single core switch.
Conversely, broad system architecture oversees how all interconnected systems interact across multiple geographic cloud regions. Automated platforms bridge this gap by translating high-level architectural goals into precise, localized device actions automatically.
The Efficiency Mindset
Embracing automated network operations requires a fundamental cultural shift toward proactive system engineering. Teams must prioritize long-term infrastructure stability and reliability over temporary, short-term manual fixes.
Instead of manually restarting a failing network interface, engineers write self-healing code that detects, isolates, and replaces faulty nodes automatically. This efficiency mindset ensures that every operational failure results in a permanent, automated software fix.
The 7 Core Principles of The Impact of Automation on Network Operations
1. Embracing Risk and Managing Variability
Absolute perfection is mathematically impossible to achieve in massive, highly complex network infrastructures. Automation frameworks focus on managing acceptable systemic risk rather than attempting to avoid all failures completely.
Engineers accept that component failures will happen and build resilient, automated software architectures to handle those failures seamlessly. This approach allows teams to roll out new features quickly while keeping overall system disruptions to a minimum.
2. Establishing Service Level Objectives (SLOs)
Modern teams rely on clear, data-driven targets to evaluate system success and keep performance steady. These targets establish measurable boundaries that keep engineering teams aligned on service quality.
| Performance Metric | Operational Definition | Target Objective |
| Availability | Percentage of successful API transactions | 99.99% Uptime |
| Latency | Time taken for packets to travel end-to-end | Less than 50ms |
Using these strict target objectives ensures that both network operations teams and product developers share clear, quantifiable goals for user experience.
3. Eliminating Toil and Manual Processes
Toil consists of repetitive, predictable, and manual operational tasks that do not add long-term value to an infrastructure. Automated network operations focus on identifying this repetitive work and engineering it away using software.
When a team eliminates manual operations, engineers free up their time to focus on strategic design work. This constant focus on automation prevents operational workloads from growing out of control as the network expands.
4. Monitoring & Observability Across the Pipeline
Complete visibility across the entire operational environment prevents dangerous technical blind spots. Modern observability platforms gather rich telemetry data from every layer of the infrastructure, including hardware switches and application endpoints.
Engineers analyze this real-time stream of metrics, logs, and traces to identify performance anomalies early. This deep visibility helps teams catch potential bottlenecks before they impact end-user performance.
5. Automation Over Manual Coordination
Scaling modern network workflows requires smart software solutions rather than human coordination across multiple teams. Software agents handle routine tasks like load balancing, path optimization, and firewall rules dynamically.
By removing manual approvals from standard deployment paths, organizations accelerate feature delivery while minimizing human errors. This software-centric model ensures consistent, predictable behavior across all production environments.
6. Release Engineering and Deployment Stability
Release engineering provides consistent, predictable, and safe application and infrastructure delivery strategies. Teams utilize automated testing frameworks to validate network configuration changes in isolated staging environments before production rollout.
[Code Commit] -> [Automated Testing] -> [Canary Deployment] -> [Production Rollout]
Canary deployments and blue-green strategies help teams introduce updates to a small fraction of live traffic first. If the system detects any performance issues, automated rollback scripts immediately restore the last known stable state.
7. Simplicity in Network Architecture
Keeping environments clean, unified, and minimal directly reduces unexpected system failure surfaces. Complex, highly customized network designs are inherently difficult to automate and prone to hidden bugs.
Engineers use standardized, modular building blocks to construct scalable, predictable network topologies. This clean architectural approach makes the infrastructure easier to monitor, automate, and troubleshoot.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the relationship between service agreements, internal objectives, and live metrics is essential for maintaining infrastructure health.
- SLA (Service Level Agreement): The overarching legal commitment made to customers regarding service uptime and performance standards.
- SLO (Service Level Objective): The stricter internal target target used by engineering teams to measure system performance and trigger warnings.
- SLI (Service Level Indicator): The actual real-time compliance percentage of a specific metric, such as current packet delivery success rates.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the total allowable downtime or performance degradation that a system can experience over a set period. For example, a 99.9% availability objective leaves a 0.1% error budget for innovation and updates.
When the error budget is full, development teams can safely ship experimental features and system upgrades. However, if unexpected outages consume that budget, the team halts all feature updates to focus exclusively on stability.
Toil — The Silent Productivity Killer in Infrastructure
Toil acts as an operational tax that slows down engineering velocity and exhausts support teams. It includes repetitive manual tasks like manually modifying DNS entries or resetting locked user ports.
Toil Calculation:
(Hours Spent on Repetitive Manual Work / Total Scheduled Working Hours) * 100
Teams calculate this metric weekly to identify which manual processes require immediate automation. Keeping toil below 50% ensures engineers have enough time to build scalable, high-performance systems.
Incident Management & Postmortems
When an unexpected network outage occurs, automated alert platforms instantly mobilize the appropriate engineering response teams. Once the service is restored, the team conducts a blameless postmortem to discover what allowed the failure to occur.
These reviews focus entirely on uncovering underlying systemic flaws rather than blaming individual engineers for mistakes. This supportive culture encourages transparency, allowing teams to turn infrastructure failures into valuable learning experiences.
Capacity Planning
Capacity planning helps engineering teams forecast data growth and scale network infrastructure ahead of sudden demand spikes. Specialists use historical traffic data to build predictive models for bandwidth, memory, and compute use.
This proactive approach helps organizations schedule automated hardware expansions or cloud provisioning windows long before bottlenecks impact live users. Proper planning prevents emergency infrastructure spending during unexpected traffic surges.
The Four Golden Signals of Pipeline Performance
To keep highly complex, distributed infrastructures running smoothly, operations teams track four core metrics:
- Latency: The total time required to process a specific network request or transmit data packets across a link.
- Traffic: A direct measure of total system demand, such as concurrent HTTP requests or overall network bandwidth usage.
- Errors: The total rate of requests that fail, such as internal routing drops or server connection timeouts.
- Saturation: A metric showing how close a system resource is to its maximum capacity, such as memory or queue limits.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Platform implementation focuses on deploying technical tools, configuring APIs, and setting up automated CI/CD infrastructure pipelines. Culture, on the other hand, centers on the team mindset of shared operational responsibility, psychological safety, and continuous learning.
Deploying cutting-edge automation tools without an open culture often results in fragmented processes and team friction. True operational efficiency happens when teams align modern software platforms with a collaborative engineering culture.
Roles & Responsibilities Compared
While both sides collaborate closely, their daily focus areas differ quite a bit:
- Platform Engineers:
- Design, construct, and maintain internal self-service developer portals.
- Build automated infrastructure templates and manage Kubernetes cluster architectures.
- Expose clean APIs to simplify hardware provisioning for application teams.
- Site Reliability Specialists:
- Monitor, measure, and protect live application availability and system performance.
- Manage error budgets and lead blameless postmortems after unexpected outages.
- Build self-healing systems to reduce manual on-call alerts.
Can You Have Both Disciplines?
Separate engineering philosophies can absolutely coexist and support each other within modern enterprises. Platform engineering groups build the automated foundations, while reliability teams protect the live production systems.
This close collaboration creates a highly efficient operational ecosystem where platform tools naturally include built-in reliability safeguards. Combined, these disciplines help enterprises deliver software updates quickly while maintaining high uptime.
Which One Should Your Team Adopt?
Choosing where to focus depends heavily on your current team size, infrastructure complexity, and engineering maturity.
| Organizational Size | Engineering Maturity Level | Recommended Primary Focus |
| Startup / Small Team | Basic cloud setup with manual deployments | Cultural alignment and basic automation |
| Mid-Market Enterprise | Growing infrastructure across multiple teams | Platform engineering for self-service tooling |
| Large-Scale Tech Global | Complex, multi-cloud microservices | Comprehensive Site Reliability Engineering |
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major tech enterprises collect billions of data points daily to monitor global infrastructure performance. They stream live network statistics into centralized analytics engines to find hidden data drop trends.
These real-time metrics allow automated traffic controllers to reroute user requests around damaged fiber lines instantly. This data-driven strategy guarantees consistent application performance for users all over the world.
Chaos Engineering Approaches to Resilient Systems
Top streaming media networks intentionally inject controlled failures into production environments to uncover hidden infrastructure bugs. Automated tools routinely shut down core routing nodes and simulate sudden cloud datacenter outages.
By testing system resilience under real-world conditions, engineers verify that automated failover paths respond quickly. This proactive chaos testing helps teams find and patch architectural weaknesses before they cause major customer outages.
Handling Reliability at Massive Scale
Distributed microservice architectures process millions of distinct transactions every single second across global networks. To survive these immense traffic volumes, organizations deploy automated service meshes to manage internal communication paths.
These service meshes provide automated load balancing, dynamic mutual TLS encryption, and instant circuit-breaking capabilities. If an individual service node slows down, the automation routes traffic away to prevent a wider system outage.
High-Availability in Fintech Operations
Financial transaction platforms have an absolute zero-tolerance policy for data packet drops or system downtime. These high-stakes environments rely on active-active network architectures that mirror transaction data across distinct geographic sites simultaneously.
Automated consensus algorithms validate data integrity across these distributed endpoints in real time. If a primary data center fails, automated routing systems shift transaction volumes immediately without losing a single financial record.
Scaled-Down but Essential Systems for Startups
Early-stage companies can easily apply these core automated principles without maintaining a large, dedicated engineering staff. Startups use managed public cloud services and open-source infrastructure tools to set up basic deployment pipelines.
By writing simple automated scripts for code deployments and monitoring system metrics early on, small teams eliminate manual work. This lightweight approach gives early-stage companies a stable foundation to scale up cleanly as their user base grows.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
Many traditional organizations mistake modern operations engineering for a simple, 24/7 on-call support rotation. This short-sighted view forces engineers to spend all their time manually responding to endless system alerts.
True operations engineering requires dedicate time to write software that resolves systemic issues permanently. Treating specialists as a manual support line stalls automation progress and leaves infrastructures vulnerable to recurring failures.
Mistake 2 — Setting Unrealistic SLOs
Demanding 100% uptime is an unrealistic objective that stalls feature updates and quickly burns out engineering teams. Perfect reliability requires massive financial investments and restricts developers from shipping necessary software improvements.
Smart organizations accept reasonable operational risks and use practical error budgets to balance system stability with product innovation. This realistic approach keeps infrastructure reliable while allowing development teams to innovate safely.
Mistake 3 — Ignoring Toil Until It’s Too Late
Ignoring manual tasks creates massive operational debt that can stall long-term engineering velocity. As an infrastructure expands, manual tasks like manual certificate renewals will consume all available engineering time.
If teams do not systematically automate these repetitive tasks, they run out of time to focus on scaling the network architecture. Proactively tracking and automating toil keeps engineering teams productive and focused on high-value projects.
Mistake 4 — Skipping Blameless Postmortems
When organizations look for a human scapegoat after a system failure, engineers learn to hide mistakes and cover up operational flaws. This blame culture prevents teams from identifying the root causes of major systemic vulnerabilities.
Blame Culture: Hides Errors -> Repeated Incidents -> Fragile Systems
Blameless Culture: Shares Insights -> Automated Fixes -> Resilient Systems
Conducting truly blameless reviews encourages engineers to share valuable technical insights openly. This transparency allows teams to build stronger, more reliable infrastructure based on past failures.
Mistake 5 — Monitoring Without Actionable Alerts
Flooding engineering teams with non-actionable notification alerts causes severe alert fatigue and leads to missed system issues. If an alert does not require immediate manual intervention, it should be logged quietly rather than paging an engineer.
Organizations must regularly audit their alerting policies to ensure that every active notification points to a clear, actionable issue. Clean alerting ensures that engineers respond quickly to critical issues that impact actual users.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Excluding operational specialists from early system architecture discussions often leads to fragile, hard-to-manage production deployments. Software developers frequently design complex application paths without considering network realities like latency or bandwidth limits.
Bringing operational engineers into design phases early ensures that new applications are built for easy automation from day one. This collaborative design strategy reduces production surprises and ensures smoother software rollouts.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Maintaining complete visibility into distributed enterprise networks requires a modern, integrated observability toolkit.
- Prometheus: An open-source time-series database engine that pulls performance metrics from endpoints.
- Grafana: A flexible visualization dashboard platform that displays real-time network and metric trends.
- Datadog: A cloud monitoring solution that provides deep cross-layer visibility and log analysis.
- New Relic: An analytics platform designed to trace application data paths through network steps.
Incident Management
When critical systems fail unexpectedly, teams rely on dedicated incident management platforms to organize their responses.
- PagerDuty: An automated routing engine that alerts on-call engineers based on live system telemetry.
CI/CD & Release Engineering
Automating network changes requires dependable deployment engines to test and push configuration code safely.
- Jenkins: A flexible automation engine used to execute custom test workflows and validate network scripts.
- Spinnaker: A multi-cloud continuous delivery platform optimized for safe infrastructure deployments.
- Argo CD: A GitOps deployment tool that matches live Kubernetes cluster states with Git code repositories.
Chaos Engineering
Testing system resilience requires specialized tools that safely inject controlled faults into production environments.
- Chaos Monkey: An automated testing tool that randomly disables production instances to verify self-healing code.
SLO Management
Tracking reliability metrics against customer agreements requires dedicated data platforms.
- Nobl9: A reliability platform that monitors SLO metrics and tracks error budget consumption in real time.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Aspiring operations experts must build a strong foundation in Linux terminal operations, system shell scripting, and basic cloud architectures. You need a strong command of Python or Go to build automated network integration scripts and interact with device APIs.
Additionally, engineers must understand core networking protocols like TCP/IP routing, DNS management, and BGP configurations. Mastering infrastructure-as-code utilities like Terraform and Ansible is also essential for automating hardware provisioning across hybrid cloud environments.
The Professional Learning Path
Your educational journey should begin by setting up simple, single-server environments and writing basic shell scripts to automate backups. Next, move on to containerizing applications using Docker and orchestrating dynamic clusters with Kubernetes.
Once you master container management, focus on building automated CI/CD pipelines that incorporate automated testing and canary deployments. Finally, study advanced systems design to learn how to build scalable, distributed networks that span multiple cloud regions.
Certifications Worth Pursuing
Industry-recognized credentials validate your technical skills and help you stand out to enterprise hiring teams. Pursuing the Certified Kubernetes Administrator (CKA) certification proves your ability to manage complex containerized environments at scale.
The AWS Certified DevOps Engineer Professional credential validates your expertise in automating deployment pipelines within cloud setups. Additionally, earning Cisco Certified DevNet certifications confirms your practical knowledge of modern network automation and programmability.
Educational Resources with Noopsschool
Building practical skills requires structured, high-quality educational programs designed by seasoned industry specialists. Aspiring professionals can access a deep library of comprehensive courses, interactive labs, and professional training resources at Noopsschool.
These expert-led programs provide hands-on experience with modern automation frameworks, continuous integration pipelines, and real-time observability suites. Utilizing these educational tools gives you the practical engineering skills needed to manage large-scale enterprise network operations.
The Future of Systems Management
AI and Automation in System Optimization
Machine learning models are changing how enterprises monitor system health and optimize network paths. Instead of relying on static alert rules, intelligent systems analyze live telemetry streams to detect anomalies early.
These AI-driven platforms can predict hardware component failures and automatically reroute traffic before an outage occurs. Integrating machine intelligence reduces the time it takes to find root causes, helping organizations resolve complex network issues within seconds.
Platform Engineering — The Evolution of Infrastructure
Platform engineering focuses on building internal self-service developer portals to simplify cloud infrastructure deployments. These internal platforms package complex network topologies, security compliance checks, and cloud resources into clean, easy-to-use APIs.
[Developer Portal API] -> [Automated Compliance] -> [Self-Service Cloud Network]
This model allows application developers to provision secure, compliant testing environments independently without waiting for manual network setups. By removing these manual coordination hurdles, platform engineering helps teams ship features faster while keeping configurations consistent.
Management in Cloud-Native & Kubernetes Environments
As organizations shift toward cloud-native microservices, managing network paths across thousands of dynamic containers becomes highly complex. Traditional IP-based security rules cannot keep pace with ephemeral containers that spin up and down constantly.
Modern operations teams rely on software-defined service meshes to discover endpoints and manage internal routing rules automatically. This shift ensures secure, high-performance communication across complex, multi-cluster Kubernetes deployments.
Operational Skills That Will Matter Most
The evolution of cloud systems is shifting engineering priorities toward deep data observability and cloud cost optimization. Future infrastructure specialists must know how to balance system performance with cloud spending limits.
Engineers will need to analyze massive telemetry datasets to find and fix hidden configuration inefficiencies. Developing these analytical and automation skills will be essential for managing sustainable, cost-effective global infrastructure networks.
FAQ Section
- What is the typical career progression for an infrastructure automation specialist?Professionals usually begin their careers as junior systems administrators or network support engineers managing basic manual device configurations. As they master programming languages and infrastructure-as-code tools, they move into dedicated platform engineering or reliability roles. Senior specialists eventually advance into enterprise architecture positions, where they design scalable, automated systems and shape global technology strategies.
- How do automation frameworks impact the average annual salary of network engineers?Adopting software development skills and automation methodologies significantly increases an infrastructure engineer’s earning potential within the global tech marketplace. Professionals who understand programmatic configuration, cloud-native orchestration, and site reliability principles command much higher salaries than traditional manual administrators. Organizations are eager to pay premium compensation for engineers who can write software to automate away expensive manual processes.
- What is the difference between an error budget and a traditional service level agreement?A service level agreement represents a formal, legal contract that outlines performance penalties and financial consequences if a service fails. In contrast, an error budget is an internal operational tool used by engineering teams to balance system innovation with baseline stability. The error budget tells developers exactly how much operational risk they can take before they must halt updates to focus on reliability.
- Can a legacy enterprise network be automated without replacing all existing hardware?Organizations can easily automate legacy networks by using modern abstraction layers, software APIs, and specialized configuration management engines. Engineers deploy automation tools that translate high-level code templates into standard CLI commands that older hardware switches can understand. This proxy approach allows companies to enjoy the benefits of automated workflows without spending money on expensive hardware upgrades.
- How frequently should an enterprise engineering team audit its performance objectives?Teams should formally audit their operational metrics and performance targets quarterly to ensure they stay aligned with evolving business needs. You should also re-evaluate your objectives whenever you launch major application updates or make significant changes to the underlying network architecture. Regular reviews ensure your targets remain challenging yet achievable without burning out engineering teams or stalling product releases.
- Which programming language is most critical for mastering modern infrastructure orchestration?Python remains the industry standard for network automation due to its simple syntax and a massive ecosystem of specialized open-source libraries. However, Go has become incredibly important for platform engineering because it powers core modern cloud tools like Kubernetes and Terraform. Mastering both languages gives infrastructure engineers the flexibility to write lightweight automation scripts and contribute to major cloud-native open-source projects.
Final Summary
Maintaining reliable, high-performance infrastructure requires moving away from fragile, manual configuration steps and embracing software-driven automation. By building clean architectures, managing clear performance targets, and removing repetitive manual processes, organizations create resilient systems that scale effortlessly. This programmatic strategy reduces human error, balances operational risk, and ensures consistent uptime during major traffic surges. Embracing an automated operational mindset helps enterprises convert unpredictable manual tasks into highly stable, self-healing code pipelines. To build the deep technical expertise needed to launch and manage these modern performance frameworks, explore the professional training programs at [Noopsschool].