Imagine a sudden, massive system disruption hitting your core infrastructure during peak traffic hours, blinding your engineering teams and halting thousands of customer transactions. This nightmare scenario highlights the dangerous operational bottlenecks that occur when organizations lack a centralized, proactive monitoring strategy. Modern enterprises require absolute uptime, yet rapidly growing infrastructure scaling introduces complex layers of vulnerability that traditional, reactive support teams simply cannot handle.
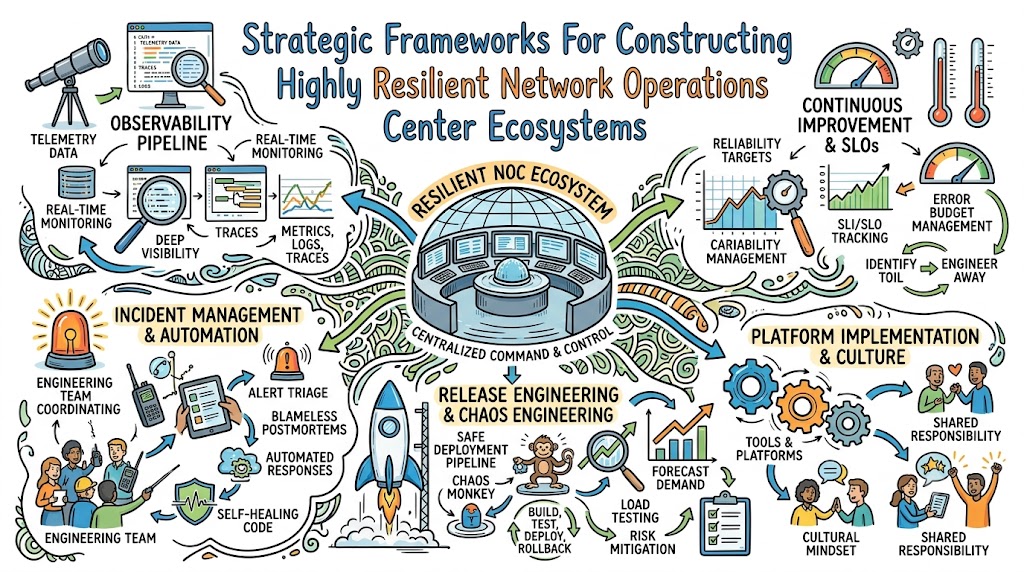
Building a Resilient Network Operations Center (NOC) serves as the definitive structural solution to this challenge by establishing a centralized, highly engineered command post that continuously monitors, manages, and secures an organization’s entire technical footprint. Unlike legacy IT service desks that merely react to broken servers, a modern resilient NOC integrates real-time observability, automated incident response, and continuous risk management to stop outages before they impact end-users. This comprehensive guide covers everything from the historical origin of systems infrastructure and strategic operations management to the core principles of reliability, operational metrics, and building an automated career path. To ensure your engineering organization possesses the advanced architectural skill sets needed to survive massive infrastructure failures, explore the deep-dive training programs and masterclasses available at Noopsschool.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise environments frequently suffered from massive operational delays due to isolated technical environments. Engineering groups designed software systems without considering how infrastructure teams would manage those systems at scale, leading to severe code deployment friction. When service disruptions occurred, the lack of centralized data visibility forced teams to waste hours passing blame instead of discovering the technical root causes of infrastructure failures.
Siloed teams struggled because they communicated through rigid, disconnected ticketing systems rather than utilizing real-time, shared telemetry data. Consequently, system administrators faced overwhelming piles of repetitive manual alerts, while developer teams remained completely unaware of the operational instability their software created. This lack of cooperative infrastructure design meant that even minor hardware or software faults could quickly cascade into catastrophic, multi-hour enterprise outages.
Moving Toward Unified Workflow Automation
As web platforms expanded globally, progressive technology enterprises realized that manual infrastructure coordination simply could not scale alongside distributed cloud systems. Organizations began breaking down these rigid organizational walls to unite software engineering practices directly with live infrastructure operations workflows. This cultural and technical shift allowed organizations to replace slow, human-dependent system administration with automated policy engines and programmatic configuration management tools.
Unifying workflows across previously disconnected operations groups drastically accelerated corporate infrastructure delivery timelines while simultaneously increasing overall system stability. Teams stopped treating infrastructure as a collection of fragile, hand-configured physical servers and began managing it as dynamic, version-controlled software code. This structural automation baseline paved the way for continuous integration pipelines, standardized incident response loops, and highly resilient system architectures.
Global Expansion Across Commercial Ecosystems
The rapid success of automated infrastructure management frameworks within cloud-native giants quickly caught the attention of traditional global enterprises. As banking, healthcare, retail, and logistics sectors migrated their core business logic to distributed cloud platforms, they eagerly adopted these advanced operational strategies. The necessity of maintaining non-stop global availability transformed infrastructure resilience from an isolated IT concern into a critical corporate metric.
Today, these unified operational frameworks span across the entire global commercial ecosystem, dictating how modern large-scale tech enterprises manage data. From localized physical server deployments to highly complex, multi-region public cloud networks, structured operational engineering keeps modern digital commerce running smoothly. Organizations that master these scaled frameworks consistently outperform their competitors by delivering software updates rapidly without sacrificing system reliability.
Defining Strategic Operations Management
The Core Operational Structure
The foundational architecture of strategic operations management relies on a continuous, closed-loop flow of telemetry data running across every infrastructure layer. High-fidelity telemetry flows seamlessly from low-level container instances up through application layers, streaming directly into centralized data aggregation systems. This real-time visibility allows automated analytics engines to parse system performance data, enabling infrastructure coordinators to spot potential system anomalies instantly.
[Infrastructure Telemetry] ──> [Centralized Data Aggregation] ──> [Automated Analytics Engines] ──> [Operational Insights]
This structural architecture ensures that every technical event, from a minor spike in network latency to a major database failure, triggers an immediate, pre-defined response. By standardizing how telemetry data travels through the monitoring pipeline, enterprises completely eliminate diagnostic guesswork during major system incidents. This rigorous data organization enables engineering teams to maintain a highly stable, completely transparent operational environment at all times.
Daily Tasks of Systems Coordinators
Systems coordinators spend their shifts executing practical, highly technical tasks designed to maintain maximum infrastructure health and efficiency. Instead of merely waiting for things to break, these specialists actively review system dashboard trends to uncover hidden bottlenecks. They routinely write automated scripts to handle predictable system alerts, update infrastructure configurations safely, and coordinate real-time incident responses during unexpected system failures.
Additionally, infrastructure specialists spend a large portion of their day collaborating with software development teams to review upcoming application deployment plans. They meticulously analyze past system incident reports to build stronger automated guardrails, ensuring that identical technical errors never happen twice. This persistent focus on structural improvement transforms daily operations from a frantic cycle of firefighting into a highly structured discipline of engineering.
Localized Control vs. Broad System Architecture
Managing complex modern infrastructure requires a deep understanding of the differences between tracking individual local components and overseeing wide, multi-system architectures. Localized control focuses entirely on the health metrics of specific application services, individual databases, or localized network switches. While this granular tracking is incredibly important, it can sometimes blind operations teams to systemic issues affecting the broader application delivery pipeline.
Broad system architecture management looks at how all these independent engineering components interact with one another across the entire global network. This macroscopic view allows operations engineers to see how a small change in a localized database could cause major performance drops down the road. Balancing granular, localized control with broad, high-level system architecture design is exactly what allows engineering teams to keep massive, distributed platforms running reliably.
The Efficiency Mindset
Transitioning to an advanced systems management framework requires a massive cultural shift toward prioritizing long-term structural stability over short-term feature delivery. This efficiency mindset demands that engineering teams treat operational reliability as an essential, non-negotiable feature of the software itself. Rather than rushing unstable code out the door, organizations focus heavily on building automated testing loops and highly resilient system guardrails.
This proactive cultural shift alters how entire engineering departments calculate and manage risk across their production environments. Teams actively celebrate finding system vulnerabilities through controlled testing because it allows them to repair architectural flaws before customers notice them. By embedding this deep reliability mindset into daily engineering workflows, organizations create a highly dependable platform capable of scaling effortlessly.
The 7 Core Principles of Building a Resilient Network Operations Center (NOC)
1. Embracing Risk and Managing Variability
This operational framework operates on the realistic premise that components will eventually fail, making absolute one hundred percent system uptime a complete mathematical impossibility. Instead of chasing an unrealistic goal of zero failures, operations engineers focus their energy on managing acceptable levels of systemic risk. They carefully balance the necessity of rapid software feature releases with the critical need for baseline infrastructure stability.
By acknowledging that technical failures are completely inevitable, teams can design highly resilient infrastructure that degrades gracefully during major system outages. This strategy ensures that a failure within a non-essential background service will never cascade to take down the primary customer transaction engine. Managing risk properly allows organizations to innovate at high speeds while keeping their core infrastructure safe and highly reliable.
2. Establishing Service Level Objectives (SLOs)
Modern operations engineering relies heavily on setting realistic, data-driven targets that define exactly what operational success looks like for the end-user. Teams work together to establish strict Service Level Objectives that keep engineering goals perfectly aligned with real customer expectations. These objectives serve as an objective technical compass, showing teams precisely when to prioritize system stability over new feature deployment.
Customer Expectations ──> Service Level Objectives (SLOs) ──> Engineering Priorities
Setting clear objectives prevents internal departments from wasting time arguing about subjective system performance levels during critical deployment cycles. These measurable performance targets provide engineering teams with a clear, mathematically sound boundary for managing system availability. Consequently, organizations can make intelligent, data-backed decisions regarding their infrastructure deployments, ensuring consistent performance without wasting expensive engineering resources.
3. Eliminating Toil and Manual Processes
Toil represents the repetitive, manual, and non-creative operational work that scales linearly with infrastructure growth and provides no long-term organizational value. Modern operations engineering wages a continuous war against this manual labor, prioritizing the systemic elimination of repetitive task management. Teams actively write automation code to handle mundane tasks like provisioning new servers, restarting stuck services, or clearing out disk space.
Engineering away this manual work frees up talented infrastructure specialists to focus on high-value, long-term architecture improvements. This relentless focus on automation keeps operational overhead incredibly low even as the broader enterprise infrastructure scales out exponentially. Eliminating toil directly prevents employee burnout, boosts team morale, and ensures that human error never compromises critical production environments.
4. Monitoring & Observability Across the Pipeline
Maintaining a highly resilient infrastructure environment requires total data visibility across every single stage of the software delivery pipeline. Modern monitoring strategies move far beyond simply checking if a server is online by implementing deep, end-to-end infrastructure observability. Engineers capture detailed metrics, structured application logs, and distributed request traces to build a crystal-clear picture of overall system health.
This pervasive visibility allows operations teams to track the precise health of an application transaction as it moves across complex microservices. Advanced observability tools help engineers discover hidden performance degradation issues before they trigger a major customer-facing outage. By completely eliminating operational blind spots, organizations can easily ensure their complex distributed networks remain highly stable and performant.
5. Automation Over Manual Coordination
When infrastructure scales up to include thousands of moving parts, relying on manual human coordination during incidents becomes an immediate operational failure point. Modern operations engineering always prioritizes software-driven automation solutions over human-centric management processes. Engineers build smart self-healing code loops that can automatically detect, isolate, and repair common infrastructure faults without human intervention.
[System Fault Detected] ──> [Self-Healing Code Loop] ──> [Isolate & Repair Fault] ──> [System Restored]
Using software code to manage complex technical infrastructure allows operations teams to execute critical tasks with absolute precision and speed. Automated configuration managers and container orchestrators ensure that every server environment remains perfectly standardized and secure. This engineering-first approach allows relatively small operational teams to manage massive, highly complex global networks with extreme efficiency.
6. Release Engineering and Deployment Stability
The process of moving software code from a developer’s computer to a live production environment must be completely predictable and safe. Operations specialists design advanced release engineering pipelines that utilize automated testing, progressive traffic shifting, and instant rollback capabilities. These stable deployment strategies ensure that any hidden software bugs are caught and isolated before they can impact the broader user base.
By standardizing and automating the release pipeline, organizations can safely deploy critical updates multiple times a day. If a new deployment causes performance degradation, the automated infrastructure system instantly rolls back to the last known stable software version. This rigorous release engineering practice drastically reduces delivery risk, ensuring that application deployment never compromises underlying system uptime.
7. Simplicity in Network Architecture
Complex software architectures are inherently difficult to monitor, troubleshoot, secure, and maintain over long operational lifecycles. Modern operations engineering intentionally prioritizes radical simplicity across all aspects of network architecture and software design. Teams actively work to reduce unnecessary software components, minimize complex data routing paths, and eliminate custom, non-standard system configurations.
Keeping enterprise environments clean and minimal directly reduces the overall failure surface area of the business. When an unexpected system incident occurs, simple architectures allow operations engineers to locate and resolve the root cause of the failure rapidly. By intentionally avoiding over-engineered technical solutions, organizations create highly stable, maintainable systems that scale beautifully over time.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Navigating modern enterprise infrastructure operations requires a crystal-clear understanding of the core reliability metrics that govern system performance. These concepts keep business agreements, internal engineering targets, and live performance metrics perfectly aligned across the organization.
- Service Level Agreement (SLA): The formal business contract that promises specific system availability levels to customers, complete with financial penalties if missed.
- Service Level Objective (SLO): The strict internal target that engineering teams aim for to ensure the system remains safely compliant with the external SLA.
- Service Level Indicator (SLI): The actual real-time measurement of system performance, calculated as the precise percentage of successful transactions.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of system downtime that an organization is willing to tolerate over a specific timeframe. Calculated directly from the internal SLO, this budget serves as an innovative tool to balance software innovation speed with system safety. For example, if an infrastructure service has a ninety-nine percent uptime SLO, it possesses a one percent error budget for acceptable failures.
As long as the error budget remains positive, software developers are free to push out new features and updates rapidly. However, if a series of system outages completely exhausts the error budget, the team must immediately pause all new feature releases. The entire engineering department then shifts its full focus toward fixing bugs and hardening infrastructure until the budget recovers.
Toil — The Silent Productivity Killer in Infrastructure
Toil is the repetitive, manual operational work that drains engineering velocity and offers absolutely zero long-term business value. To help teams identify and systematically eliminate this administrative drag, consider the core characteristics of toil detailed below.
| Attribute | Description |
| Manual | Requires direct human intervention, such as running commands manually in a terminal. |
| Repetitive | Occurs repeatedly, requiring identical resolution steps every single time. |
| Automatable | Can be easily resolved using standard scripting languages or automation engines. |
| Tactical | Focuses entirely on immediate, short-term fixes rather than strategic improvements. |
| Scales Linearly | Grows larger as the underlying infrastructure expands, demanding more staff. |
To eliminate this productivity killer, teams must ruthlessly analyze their daily workloads to identify repetitive, non-creative tasks. Once identified, engineers must dedicate specific sprint cycles to writing automation scripts that handle these tasks permanently. Systematically removing this manual work allows organizations to keep their operational teams highly focused on strategic architecture projects.
Incident Management & Postmortems
When a severe operational outage strikes, a well-defined, highly structured incident management process is absolutely vital for rapid recovery. Teams assign clear operational roles, such as an incident commander to lead the recovery and a communications lead to update stakeholders. Once the technical issue is completely resolved, the engineering team shifts to conducting a rigorous, blameless postmortem.
A blameless culture assumes that engineers always make the best choices with the data they had at the time. Instead of pointing fingers at individuals, the postmortem focuses entirely on discovering the underlying structural flaws that allowed the human error to occur. Writing detailed, public postmortems helps teams turn painful infrastructure failures into invaluable lessons that permanently strengthen system resilience.
Capacity Planning
Capacity planning is the highly structured discipline of forecasting future resource needs to prevent system degradation before usage spikes occur. Operations engineers analyze historical system trends, organic business growth data, and upcoming marketing campaigns to calculate future infrastructure demands. This proactive data analysis allows teams to secure cloud resources and optimize hardware allocations well ahead of time.
Proper capacity planning ensures that the platform can handle massive, sudden traffic surges without experiencing severe latency spikes or database crashes. Teams use advanced cloud scaling policies alongside regular load-testing simulations to verify how their systems behave under extreme stress. By staying ahead of consumer demand, enterprises protect their brand reputation and deliver a completely flawless user experience.
The Four Golden Signals of Pipeline Performance
To maintain deep visibility into distributed system environments, operations teams must monitor the four golden signals of performance. Tracking these critical technical metrics allows engineers to quickly isolate hidden system errors and system bottlenecks.
- Latency: The precise time it takes to successfully process a specific request, separating successful request times from failed request times.
- Traffic: The overall demand being placed on the infrastructure network, measured in network requests per second or concurrent data sessions.
- Errors: The rate of incoming requests that are failing catastrophically, measured across explicit software errors and implicit performance policy failures.
- Saturation: The measurement of system resource utilization, highlighting exactly how close an individual infrastructure component is to reaching its maximum operating capacity.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many organizations mistakenly assume that deploying advanced monitoring software is all it takes to build a modern, resilient operations framework. In reality, platform implementation focuses entirely on provisioning technical tools, configuring telemetry pipelines, and building real-time system visualization dashboards. While these software tools are absolutely necessary, they are ultimately ineffective without a supporting operational culture.
The underlying engineering culture dictates exactly how human teams behave, communicate, and react to system data over long lifecycles. A true reliability culture embraces systemic risk, treats operational failures as learning opportunities, and prioritizes long-term automation over fast, manual fixes. Without this supportive cultural mindset, teams will simply use their expensive new monitoring platforms to fight fires reactively.
Roles & Responsibilities Compared
Understanding how day-to-day duties differ between specific engineering disciplines is essential for structuring highly efficient technical organizations. While both groups focus heavily on maintaining infrastructure health, their day-to-day tasks target entirely different operational areas.
- Platform Engineers: Focus on building internal developer tools, maintaining shared infrastructure platforms, and automating continuous deployment pipelines.
- Operations Specialists: Concentrate on managing real-time incident responses, monitoring live application telemetry, and tracking service level objectives.
- Site Reliability Engineers: Devote their time to writing software code that eliminates manual toil, conducting postmortems, and improving core system resiliency.
- System Administrators: Handle localized user access controls, manage individual operating system updates, and troubleshoot specific physical hardware issues.
Can You Have Both Disciplines?
Modern enterprise organizations do not have to choose between deploying advanced engineering platforms and cultivating a healthy reliability culture. In fact, separate engineering philosophies coexist beautifully and actively reinforce one another within high-performing technology companies. The technical platform provides the deep visibility and automation tools that allow cultural methodologies to work efficiently at scale.
When these engineering disciplines are aligned, the platform team builds the automated guardrails that help operations engineers manage systemic risk safely. This powerful combination allows organizations to deploy software updates rapidly while keeping their overall production environments incredibly stable. Embracing both technical platforms and cultural philosophies helps enterprises construct a robust, highly adaptable engineering organization.
Which One Should Your Team Adopt?
Deciding where to focus your organizational energy depends heavily on your current company size, system complexity, and overall engineering maturity. Small startups with simple application setups should focus on building a strong culture of shared operational responsibility first. At this early stage, avoiding over-engineered platforms prevents unnecessary overhead while keeping the team highly agile.
| Organization Size | Primary Focus | Recommended Action |
| Startup | Cultural Foundation | Establish shared operational habits and simple, clean application architectures. |
| Mid-Market | Platform Automation | Build centralized internal platforms to standardize deployments across teams. |
| Enterprise | Integrated Strategy | Combine deep platform engineering with structured site reliability cultures. |
As an organization grows into a large enterprise, investing heavily in dedicated platform engineering becomes an absolute necessity. Large scale introduces complex multi-team dependencies that cannot be managed through culture alone without standardized, automated internal infrastructure. Matching your technical strategy to your organizational maturity level ensures long-term operational success without wasting budget.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major global software enterprises track real-time operational data to keep their complex distributed systems functioning perfectly at scale. These companies feed millions of data points into centralized machine learning engines to spot subtle performance anomalies instantly. By monitoring real-time metrics across thousands of microservices, they can isolate and fix code regressions before users notice them.
These tech leaders actively share their operational data across all internal engineering departments to drive continuous system optimization. Developers use these live infrastructure insights to write cleaner, more efficient code that consumes fewer cloud resources. This deep data transparency breaks down walls between teams, aligning everyone around the shared goal of absolute system reliability.
Chaos Engineering Approaches to Resilient Systems
Highly resilient organizations do not simply sit around waiting for natural infrastructure failures to strike their production environments. Instead, they practice chaos engineering, which involves intentionally injecting controlled faults into live systems to find hidden vulnerabilities. Engineers regularly take down entire server groups, cause network delays, or break background services on purpose.
This proactive testing allows teams to verify that their automated self-healing systems and failover policies work exactly as designed. By uncovering hidden architectural flaws during safe business hours, engineers can fix them long before an unexpected outage occurs. Running regular chaos experiments builds incredible system resilience and gives operations teams massive confidence in their platform’s stability.
Handling Reliability at Massive Scale
Managing distributed microservices that process millions of global transactions every second requires a complete departure from traditional infrastructure operations. Massive cloud platforms utilize dynamic container orchestrators to distribute workloads intelligently across multiple global data centers simultaneously. If a massive hardware failure takes down an entire cloud region, automated traffic managers instantly reroute users to the nearest healthy data center.
[Global Traffic Manager]
/ \
/ \
[Healthy Data Center Region] [Failed Cloud Region (OFFLINE)]
At this extreme scale, systems are engineered to self-heal continuously without requiring slow human intervention during late-night outages. Automated configuration systems dynamically scale cloud resources up or down in real time based on changing consumer traffic patterns. This hyper-automated approach allows modern digital platforms to maintain flawless availability despite facing constant hardware and network failures.
High-Availability in Fintech Operations
Financial technology and payment processing networks operate under absolute zero-tolerance policies for service downtime or data loss. A single minute of network latency or system unavailability can result in millions of dollars in lost revenue and severe regulatory fines. To maintain non-stop availability, fintech operations teams deploy highly redundant, multi-region database architectures that sync data continuously.
These teams monitor transactional data streams with extreme precision, setting tight alert thresholds for even the tiniest performance dips. Every single layer of the payment pipeline features automated, instant failover guardrails to protect active user transactions. Combining strict financial security controls with modern reliability engineering ensures that global money transfers remain completely safe, accurate, and available.
Scaled-Down but Essential Systems for Startups
Early-stage technology startups often lack the massive engineering budgets and large operations teams found within established global enterprises. However, these agile companies can still apply core reliability principles efficiently without introducing complex technical overhead. Startups use managed cloud services and lightweight monitoring tools to automate their infrastructure deployments from day one.
By focusing on building clean application code and setting up basic, actionable alerts, small teams can protect their core user experience. Automating simple tasks, like database backups and server restarts, helps early-stage startups eliminate major operational bottlenecks. This early investment in basic system health builds a highly stable foundation that allows the business to scale smoothly as customer demand grows.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
One of the most damaging mistakes an enterprise can make is treating operations teams as a reactive cleanup crew that only handles alerts. When engineers spend their entire shift frantically responding to pages, they have zero time left to fix the underlying architectural flaws causing those failures. This reactive firefighting pattern creates an unsustainable cycle that burns out talented specialists and keeps systems highly unstable.
Modern operations engineering is a proactive discipline focused on writing smart automation code to prevent incidents entirely. Teams must be given the dedicated time and authority to build resilient infrastructure guardrails that handle common system faults automatically. Shifting your operational approach from manual firefighting to proactive system engineering is the only way to achieve true, long-term infrastructure stability.
Mistake 2 — Setting Unrealistic SLOs
In an effort to impress customers, leadership teams often demand unrealistic system uptime goals, like one hundred percent absolute availability. Demanding perfection completely stalls software engineering velocity because it forces teams to stop releasing updates at the slightest hint of risk. This restrictive environment creates intense friction between feature developers trying to move fast and operations teams trying to maintain stability.
Setting unrealistic performance targets also leads to severe employee burnout as engineers waste time chasing unachievable metrics. Organizations must realize that minor system failures are a natural, inevitable part of running complex distributed environments. Establishing realistic, data-backed objectives allows teams to balance rapid software innovation with a dependable customer experience.
Mistake 3 — Ignoring Toil Until It’s Too Late
When companies rapidly expand their software platforms, they often ignore repetitive, manual tasks like clearing logs or provisioning servers manually. Over time, this operational debt accumulates rapidly, creating a massive administrative drag that completely blocks engineering velocity. Operations teams become so overwhelmed by repetitive manual tasks that they lose the ability to focus on critical infrastructure improvements.
Ignoring this growing pile of manual work causes severe project delays, introduces human errors, and burns out your best engineering talent. Organizations must actively track their daily workloads and ruthlessly automate repetitive tasks before they overwhelm the team. Treating toil as a dangerous operational disease ensures your engineering organization remains lean, fast, and highly efficient.
Mistake 4 — Skipping Blameless Postmortems
When a severe production outage occurs, a toxic corporate culture will immediately look for a human scapegoat to blame for the mistake. This finger-pointing behavior forces engineering teams to hide their mistakes, cover up system vulnerabilities, and avoid taking innovative technical risks. Without open communication, the underlying architectural flaws that allowed the human error to happen remain unfixed in production.
Skipping or rushing through the postmortem process guarantees that identical system failures will continue to impact your business. Organizations must build a supportive environment that prioritizes open, objective analysis over personal blame. Conducting honest, blameless postmortems is the only way to uncover root causes and build permanent automated guardrails.
Mistake 5 — Monitoring Without Actionable Alerts
Many operations teams mistakenly believe that more alerts automatically equal better system monitoring, leading them to configure notifications for every minor metric spike. This approach quickly floods communication channels with non-critical alerts, causing severe alert fatigue across the entire engineering department. Overwhelmed engineers eventually start ignoring notifications, causing them to completely miss real, catastrophic system failures when they occur.
[Too Many Non-Critical Alerts] ──> [Alert Fatigue] ──> [Engineers Ignore Notifications] ──> [Missed System Failures]
Every single alert configured in your monitoring pipeline must be actionable and indicate a real, customer-impacting problem. If an alert does not require an immediate, human response to fix a broken system, it should be logged quietly or automated away. Streamlining your alerting systems keeps your operations team highly focused, calm, and ready to respond quickly when true emergencies arise.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Software development teams frequently design complex application architectures without consulting the operations specialists who will eventually support them. This isolation leads to the deployment of fragile software systems that are incredibly difficult to monitor, secure, and scale in production. When an unexpected outage occurs, the lack of operational input during design makes troubleshooting a slow and painful process.
Systems architecture design absolutely requires deep operational engineering feedback from the very first day of planning. Operations specialists bring invaluable real-world experience regarding how distributed systems fail under extreme consumer traffic loads. Involving these experts early helps teams build highly observable, resilient platforms that are easy to maintain over long lifecycles.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Building a highly resilient infrastructure requires a modern software stack designed to collect, analyze, and visualize deep system telemetry data. Industry-leading monitoring platforms provide the absolute data foundation needed to track system health across complex, distributed networks.
- Prometheus: An open-source time-series database designed for highly scalable, metrics-driven monitoring and precise alerting.
- Grafana: A powerful visualization engine that builds real-time, customizable dashboards to track complex data streams.
- Datadog: A unified cloud observability platform providing full-stack application tracking, log management, and security monitoring.
- New Relic: An all-in-one observability platform that helps engineers optimize software performance across the entire pipeline.
Incident Management
When a critical production outage strikes, communication and response coordination must be completely automated to ensure rapid resolution. Advanced incident management tools route alerts to the right on-call engineers instantly and help teams collaborate effectively during emergencies.
- PagerDuty: An automated incident response platform that coordinates on-call schedules, routes critical alerts, and accelerates system recovery.
CI/CD & Release Engineering
To maintain total deployment stability, organizations rely on automated software continuous integration and deployment pipelines. These automation engines ensure that every single code update is thoroughly tested and deployed safely without causing user downtime.
- Jenkins: A flexible, open-source automation server used to build highly customized continuous integration and delivery pipelines.
- Spinnaker: A multi-cloud continuous delivery platform designed for fast, repeatable, and high-availability application deployments.
- Argo CD: A declarative GitOps deployment tool built specifically to manage Kubernetes container configurations safely.
Chaos Engineering
Proactively testing system resilience requires advanced tools designed to inject controlled failures into live production environments safely. These specialized platforms help engineers uncover hidden architectural flaws before they cause real customer outages.
- Chaos Monkey: A resilient testing tool that randomly terminates live server instances to ensure systems handle failures gracefully.
SLO Management
Tracking system reliability metrics against strict user thresholds requires specialized platforms that calculate error budgets in real time. These tools help business and engineering teams stay perfectly aligned around shared availability targets.
- Nobl9: A dedicated service level objective platform that tracks reliability data and alerts teams before error budgets empty.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Starting a career in modern operations engineering requires mastering a core set of foundational command-line tools and software scripting languages. Aspiring specialists must feel completely comfortable navigating Linux terminal environments, managing file systems, and configuring secure network paths. They need to write clean automation scripts using languages like Python or Go to eliminate repetitive manual task management.
Additionally, professionals must develop a deep understanding of cloud computing concepts, virtualization systems, and container technologies like Docker. Understanding how modern applications communicate across distributed networks is absolutely vital for diagnosing complex latency issues. Combining strong software programming skills with a deep knowledge of systems infrastructure makes you an invaluable asset to any modern enterprise.
The Professional Learning Path
The journey to becoming a senior infrastructure architect requires a structured, step-by-step educational progression through increasingly complex technical domains. Beginners should start by managing single server environments, writing basic automation scripts, and configuring simple application monitoring dashboards. Once these core system administration skills are fully mastered, learners can transition to exploring advanced container orchestration systems like Kubernetes.
Next, engineers should focus on mastering continuous integration pipelines, infrastructure-as-code frameworks, and advanced distributed systems design. Professionals must also learn how to translate high-level business requirements into clear, measurable service level objectives. Continually expanding your engineering skill set allows you to easily step into senior leadership roles that guide major digital transformation projects.
Certifications Worth Pursuing
Industry-recognized technical credentials serve as an excellent way to validate your infrastructure expertise and accelerate your career growth. Earning respected certifications proves to global employers that you possess the practical, hands-on skills needed to manage complex systems.
- Certified Kubernetes Administrator (CKA): Validates your practical ability to build, configure, and manage production-ready Kubernetes container clusters.
- AWS Certified DevOps Engineer — Professional: Demonstrates your expertise in automating, securing, and managing complex distributed architectures on cloud platforms.
- Google Cloud Professional Cloud DevOps Engineer: Certifies your ability to deploy stable software pipelines, manage error budgets, and monitor live system performance.
Educational Resources with Noopsschool
Navigating the rapidly evolving world of modern infrastructure operations can feel incredibly overwhelming without structured guidance and expert mentorship. Fortunately, Noopsschool provides a comprehensive selection of deep-dive training programs designed to transform ambitious learners into elite operations experts. Their highly practical, hands-on courses mirror real-world production environments, ensuring you gain the actual engineering skills demanded by top global tech enterprises.
Whether you are looking to master complex container orchestration, build automated monitoring pipelines, or cultivate a healthy site reliability culture, their expert-led curriculum has you covered. Students receive direct, hands-on experience using cutting-edge industry tools like Prometheus, Grafana, Kubernetes, and automated incident management engines. Investing in your technical education through their structured training platforms gives you the deep architectural knowledge needed to lead high-performing engineering teams with total confidence.
The Future of Systems Management
AI and Automation in System Optimization
Artificial intelligence and machine learning models are rapidly transforming how global enterprises monitor and optimize their core infrastructure. Modern operations frameworks use intelligent analytics engines to track millions of telemetry data streams and identify subtle performance drops instantly. These smart systems can forecast impending hardware failures well before they happen, allowing teams to swap components safely without causing service interruptions.
Machine intelligence also drastically accelerates root-cause analysis by instantly sorting through mountains of application logs during active system incidents. This automated data parsing helps incident commanders isolate and resolve complex software bugs in a fraction of the time. As AI technology continues to mature, systems management will shift completely from a human-driven monitoring discipline to a highly intelligent, self-optimizing ecosystem.
Platform Engineering — The Evolution of Infrastructure
Platform engineering is rapidly emerging as the next major step in the evolution of modern enterprise software delivery. Instead of forcing software developers to manage complex cloud configurations, specialized platform teams build automated, self-service internal developer portals. These unified platforms allow developers to safely provision databases, run tests, and deploy microservices with a few simple clicks.
[Software Developers] ──> [Self-Service Internal Portal] ──> [Automated Cloud Provisioning]
Standardizing the software delivery pipeline allows organizations to bake security policies and reliability guardrails directly into the platform itself. This automated approach drastically reduces operational friction, prevents configuration errors, and allows development teams to move at lightning speeds. Platform engineering empowers organizations to scale out their development operations safely without compromising the underlying stability of production environments.
Management in Cloud-Native & Kubernetes Environments
The massive adoption of dynamic container orchestrators like Kubernetes introduces unique, highly complex scaling challenges that traditional operations tools cannot handle. Modern cloud-native environments feature thousands of short-lived container instances that spin up and down continuously based on real-time traffic demand. Managing these highly fluid architectures requires deep, end-to-end network observability and automated configuration tracking across the entire cluster.
Operations teams must deploy specialized service meshes and microservice tracing networks to watch how data travels across ephemeral environments. Engineers use declarative GitOps workflows to ensure that live cluster configurations always match the version-controlled code stored in secure repositories. Mastering these complex orchestration frameworks is absolutely essential for keeping modern cloud-native systems highly available, secure, and performant.
Operational Skills That Will Matter Most
As infrastructure systems grow increasingly complex and cloud-dependent, the technical skill sets required by operations specialists are shifting rapidly. Organizations are placing a massive premium on financial cost optimization skills, demanding that engineers build highly efficient systems that minimize cloud spending. Specialists must learn how to design automated scaling systems that dynamically adjust resources to eliminate expensive, idle hardware waste.
Additionally, professionals must master advanced data observability techniques to easily trace request paths across complex multi-cloud architectures. Developing a deep understanding of chaos engineering experiments and automated self-healing system design will become an absolute necessity for senior roles. Cultivating these forward-looking engineering skills ensures you remain a highly sought-after technical expert capable of steering global infrastructure strategies.
FAQ Section
- What is the standard career progression path for a modern infrastructure operations specialist?Professionals typically begin their careers as junior systems administrators or monitoring technicians, focusing on localized alert management and basic troubleshooting. As they master programming scripts and cloud tools, they move up into dedicated site reliability engineering or platform engineering roles. Senior specialists eventually advance into enterprise infrastructure architects or director-level positions, where they design broad system architectures and guide global technical strategies.
- How does modern operations engineering differ fundamentally from traditional IT support roles?Traditional IT support operates within a purely reactive framework, waiting for a server component to fail before manually intervening to fix the issue. Modern operations engineering is a proactive, software-driven discipline that focuses heavily on writing automation code to prevent infrastructure incidents entirely. These specialists spend their time designing resilient system guardrails, tracking error budgets, and building end-to-end observability pipelines to ensure long-term stability.
- What are the current salary trends for certified reliability and platform engineers globally?Due to the extreme complexity of managing distributed cloud networks, certified infrastructure experts remain among the highest-paid professionals in technology. Mid-level reliability and platform engineers consistently command excellent compensation packages that reflect their specialized software and systems expertise. Senior infrastructure architects who possess deep cloud automation skills frequently secure premium salaries and leadership bonuses at major technology enterprises.
- Why is a blameless postmortem culture considered essential for maintaining high system uptime?A blameless culture assumes that engineers always try to do the right thing and that failures are caused by flawed system designs rather than bad employees. If you punish individuals for mistakes, teams will actively hide system vulnerabilities to protect themselves, leaving hidden defects unfixed in production. Conducting open, blameless postmortems encourages total transparency, allowing teams to uncover true root causes and build permanent automated guardrails.
- How do teams calculate an error budget, and what happens when it is completely exhausted?An error budget is calculated mathematically as the exact amount of system downtime tolerated by an internal Service Level Objective. For example, a ninety-nine percent uptime objective over a month leaves a one percent budget for acceptable system failures. If a series of outages completely empties this budget, feature releases are paused immediately so all engineering focus can shift to hardening infrastructure.
- Which programming languages are most valuable for automating modern cloud infrastructure networks?Python remains an incredibly popular and valuable language due to its simple syntax, extensive library support, and excellent integration with cloud platform APIs. Go has also become an industry standard for cloud-native engineering because it powers core modern infrastructure tools like Docker and Kubernetes. Learning to use these languages alongside bash scripting allows engineers to automate manual toil and build highly resilient systems.
Final Summary
Maintaining flawless system health across modern enterprise networks requires a complete departure from traditional, reactive firefighting tactics toward proactive engineering. Organizations must ruthlessly automate away manual toil, establish clear service level objectives, and embed total observability across their entire application deployment pipeline. Balancing platform automation with a deeply cooperative, blameless culture allows businesses to release innovative features rapidly while keeping core infrastructure incredibly secure. Ultimately, constructing a resilient network operations center environment acts as the definitive shield that protects your digital platform from catastrophic downtime. To position your engineering organization at the absolute cutting edge of performance frameworks and modern system design, explore the expert-led curriculum at Noopsschool.