A single undetected network bottleneck can freeze global transactions, halt production lines, and disconnect millions of users in seconds. When primary network systems experience unexpected latency or structural downtime, businesses face immediate financial loss and long-term reputational damage. Modern technology landscapes demand more than reactive troubleshooting because distributed architectures move too fast for manual intervention. Organizations need systematic, data-driven frameworks to maintain resilient data pipelines and high-performing environments.
Network operations engineering addresses these modern complexities by combining software development practices with infrastructure management. This comprehensive discipline replaces traditional, reactive firefighting with proactive automation, clear system visualization, and structured risk assessment. By implementing these practices, scaling teams ensure continuous uptime and steady data delivery across hybrid cloud environments. Throughout this extensive guide, we will analyze foundational systemic bottlenecks, operational management frameworks, and reliable automation strategies.
This deep-dive roadmap explores the historical roots of systems infrastructure, the core principles of reliability, and essential metrics like error budgets. You will learn to distinguish between cultural practices and concrete platform implementations while avoiding common infrastructure pitfalls. We also break down the modern tooling ecosystem and provide a clear career pathway for aspiring infrastructure specialists. To master these advanced architectural methods and ensure continuous infrastructure availability, teams can access comprehensive technical resources through Noopsschool to transform their operational capabilities.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise environments relied heavily on isolated engineering departments that functioned independently. Software developers focused entirely on shipping new features quickly, while network administrators prioritized keeping the local infrastructure stable and unchanged. Consequently, this deep division created systemic operational blockages, as code deployments frequently conflicted with rigid network configurations.
Manual setups dominated the landscape, meaning that setting up servers, routing tables, and firewalls required tedious, hands-on intervention. Because human operators completed these tasks individually, configuration drifts occurred frequently, making identical environments behave differently. When outages happened, teams spent hours blaming each other rather than identifying the true technical root causes.
As software applications expanded into distributed web environments, this old method became completely unsustainable. Manual tracking could not keep up with the rapid acceleration of user traffic and data processing needs. This clear operational breaking point forced industry leaders to seek an engineering-centric approach to manage infrastructure at scale.
Moving Toward Unified Workflow Automation
The integration of software engineering practices into network operations completely changed how enterprises handle infrastructure. Instead of treating infrastructure as a collection of static hardware boxes, teams began defining networks and systems through executable code. This major shift allowed operations specialists to use version control systems, automated testing patterns, and continuous integration pipelines.
Breaking down historical silos meant that development and operations teams started sharing metrics, goals, and systemic responsibilities. Workflow automation replaced repetitive manual typing, which eliminated human error from routine system deployments. Consequently, updates became predictable, repeatable, and fast, allowing organizations to deploy changes multiple times a day.
Furthermore, this evolution established a culture of shared systemic accountability across corporate environments. Engineers developed automated testing scripts to validate network performance before push operations occurred in live production. Ultimately, this structural shift laid the foundation for modern cloud-native reliability and self-healing system frameworks.
Global Expansion Across Commercial Ecosystems
Once large enterprise technology providers demonstrated the success of automated systems management, these frameworks spread rapidly across different industries. E-commerce platforms, global financial institutions, and logistics corporations adopted these architectural patterns to safeguard their digital storefronts. As a result, maintaining high network availability transformed from an internal IT concern into a critical business priority.
The global expansion of cloud computing accelerated this movement by providing instant access to programmable virtual infrastructure. Organizations of all sizes suddenly had to manage complex web architectures spanning multiple geographic regions simultaneously. Consequently, the demand for dedicated systems coordinators who understood both software development and network topology skyrocketed worldwide.
Today, these operational frameworks govern the infrastructure of nearly every major enterprise running digital services. Modern tech ecosystems require continuous delivery pipelines that adapt automatically to changing traffic loads without human intervention. By standardizing these operational practices globally, the technology sector established a new baseline for software resilience and network performance.
Defining Strategic Operations Management
The Core Operational Structure
Strategic operations management coordinates software code, physical hardware, and cloud networking components into a unified system. Information flows continuously through automated monitoring pathways, providing visibility into every layer of the infrastructure stack. The structure relies on feedback loops where system metrics immediately inform automated scaling policies and alerting platforms.
[User Request] ➔ [Edge Routing / Load Balancer] ➔ [Application Microservices]
│
(Telemetry Data)
▼
[Automated Remediation] ◄── [Alerting / Rules Engine] ◄── [Observability Pipeline]
By maintaining this open architectural loop, operations engineers can observe systemic anomalies before they impact end users. This core structure prioritizes predictability, ensuring that data packets move along optimized pathways with minimal resistance. This systematic mapping of dependencies allows teams to pinpoint vulnerabilities and reinforce weak nodes across the entire enterprise network.
Daily Tasks of Systems Coordinators
Systems coordinators execute a variety of engineering and administrative tasks daily to ensure continuous system health. They spend a significant portion of their day writing automation scripts to eliminate repetitive maintenance tasks. Additionally, these specialists configure telemetry dashboards to track live traffic patterns and system behavior.
- Reviewing System Performance: Analyzing network logs and telemetry data to detect performance degradation or unexpected capacity constraints across clusters.
- Managing Configuration Code: Writing, testing, and merging infrastructure-as-code updates to modify routing policies or scale computing resources safely.
- Conducting Blameless Investigations: Leading post-incident reviews to determine the structural root causes of recent systemic anomalies or unexpected service downtimes.
- Optimizing Resource Allocation: Adjusting cloud resource distributions and load balancer algorithms to balance operational costs with performance targets.
Localized Control vs. Broad System Architecture
Understanding the distinction between granular component tracking and broad system architecture is essential for scaling modern operations. Localized control focuses on individual elements, such as checking a specific server’s CPU usage or monitoring a single router’s port status. While this detailed tracking remains necessary, focusing exclusively on isolated components often causes teams to miss widespread systemic failures.
In contrast, broad system architecture looks at the entire multi-system infrastructure as an interconnected organism. This macro-level view prioritizes how different applications, databases, and network paths interact under heavy workloads. Operations engineers use this comprehensive perspective to optimize global data traffic, build redundant failover routes, and protect system integrity during regional cloud outages.
The Efficiency Mindset
Transitioning to modern operations requires a profound cultural shift that prioritizes long-term system stability over short-term fixes. Engineers with an efficiency mindset refuse to accept recurring manual work as a normal part of their daily routines. Instead, they view every system failure as an opportunity to build automated defenses that prevent similar issues from happening again.
This mindset encourages calculated risk-taking by using clear data metrics to balance feature innovation with platform safety. Teams accept that systems will occasionally experience anomalies, so they design software environments to tolerate failures gracefully. Ultimately, this proactive approach reduces operational stress, eliminates late-night emergency alerts, and helps organizations maintain a reliable user experience.
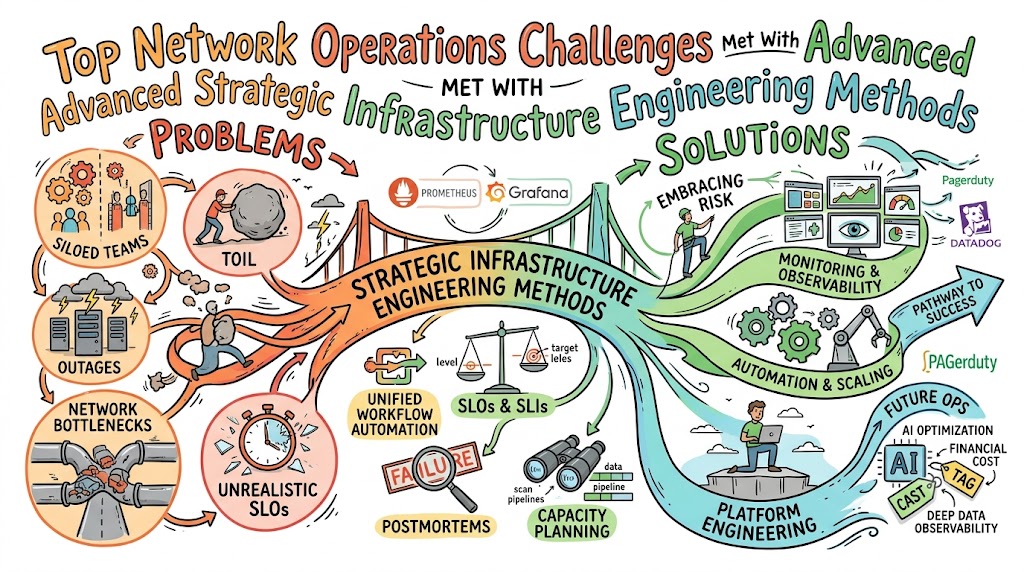
The 7 Core Principles of Top 5 Network Operations Challenges and How to Overcome Them
1. Embracing Risk and Managing Variability
Modern operations engineering recognizes that achieving absolute 100% uptime is mathematically impossible and economically impractical. Trying to eliminate every single drop of downtime requires massive financial investments that yield diminishing returns for the business. Therefore, teams focus on defining an acceptable level of systemic risk that allows development velocity to continue smoothly.
By embracing variability, engineers design resilient software architectures that can withstand individual component failures without collapsing entirely. They use partial degradation strategies, allowing non-essential features to turn off automatically during traffic spikes while keeping core transactional systems active. This realistic approach shifts the focus from avoiding all risk to managing risk intelligently through data-driven operational boundaries.
2. Establishing Service Level Objectives (SLOs)
Service Level Objectives serve as the primary foundational targets for measuring the success and reliability of an operational environment. These objectives define clear, quantitative performance goals that teams must meet over a specific timeframe, such as a month. For example, a team might set an SLO stating that 99.9% of user database queries must return answers in less than 200 milliseconds.
+------------------------------------------------------------+
| Service Level Indicator (SLI) |
| "The actual measurement: Current latency is 150ms." |
+------------------------------------------------------------+
│
▼
+------------------------------------------------------------+
| Service Level Objective (SLO) |
| "The internal target: Keep latency below 200ms for 99.9%" |
+------------------------------------------------------------+
│
▼
+------------------------------------------------------------+
| Service Level Agreement (SLA) |
| "The legal contract: If SLO fails, we credit the client." |
+------------------------------------------------------------+
Setting precise SLOs prevents business decisions from being driven by vague emotional complaints about system speed. These objectives create a common language between product managers, software developers, and infrastructure engineers regarding platform stability. By tracking these metrics continuously, teams can make objective, data-backed choices about whether to ship new features or focus on stabilizing infrastructure.
3. Eliminating Toil and Manual Processes
Toil represents the repetitive, predictable, and manual operational work that keeps a system running but adds no long-term value. Examples of toil include manually resetting full disk drives, running repetitive script commands weekly, or manually approving basic firewall rules. Left unchecked, toil drains engineering productivity, causes human errors, and burns out talented infrastructure specialists.
Modern operations engineering sets strict limits on the amount of toil a team can handle, typically capping it at 50% of their working hours. Engineers spend the remaining half of their time writing automation code, refactoring infrastructure, and designing self-healing software mechanisms. Consequently, when a disk drive fills up, an automated daemon script clears temporary files instantly, eliminating the need for manual intervention.
4. Monitoring & Observability Across the Pipeline
Comprehensive visibility across the entire data pipeline is necessary to prevent operational blind spots in modern distributed networks. Traditional monitoring simply alerts teams when a component breaks, but observability helps engineers understand why a complex system is behaving strangely. This advanced approach requires collecting telemetry data across three main pillars: structured logs, real-time metrics, and distributed request traces.
By analyzing these three data streams together, operations engineers can track an end-user request as it travels through complex network paths and backend microservices. This deep visibility allows teams to catch silent errors, isolate performance drops, and optimize slow database queries before they escalate into major outages. Effective observability ensures that engineers make optimization decisions based on actual performance data rather than guessing.
5. Automation Over Manual Coordination
Scaling modern systems efficiently requires replacing human coordination with automated, programmatic software solutions. When a system needs to scale up due to a sudden traffic spike, manual provisioning is simply too slow to prevent downtime. Therefore, operations engineers build smart software control loops that monitor system demand and launch new virtual infrastructure instantly.
This principle applies to all areas of infrastructure management, including automated network routing, certificate renewals, and database backups. Automation ensures that every operational action happens exactly the same way, completely removing the unpredictability of manual configuration changes. By relying on software code to coordinate complex systems, organizations can manage thousands of servers with minimal operational overhead.
6. Release Engineering and Deployment Stability
Release engineering focuses on the strategies, tools, and practices used to compile, test, and deploy applications safely and reliably. Stable deployment practices protect production environments from sudden shocks when new software code goes live. Teams use canary deployment patterns, where updates roll out to a tiny fraction of users before expanding to the entire network.
[New Code Version] ➔ [Deploy to 2% Canary Group] ──► (Monitor Error Rates)
│
┌──────────────────────────────────────┴──────────────────────────┐
▼ (Errors Detected) ▼ (Healthy Metrics)
[Instant Rollback] [100% Global Rollout]
Blue-green deployment strategies also reduce operational risk by maintaining two identical production environments simultaneously. One environment handles live user traffic, while the other receives the new software update for final validation. If any anomalies appear during testing, the load balancer routes traffic back to the safe environment instantly, ensuring zero disruption for users.
7. Simplicity in Network Architecture
Complex network environments are inherently fragile because they contain too many hidden dependencies and potential points of failure. Every extra layer of custom routing rules, legacy hardware workarounds, and non-standard configurations increases the risk of unexpected downtime. Therefore, operations engineers prioritize architectural simplicity, keeping infrastructure designs clean, modular, and easy to understand.
Maintaining simplicity requires teams to regularly decommission obsolete microservices, standardize network protocols, and document data paths clearly. Simple architectures make it much easier for engineers to isolate system problems quickly during high-stress troubleshooting situations. By reducing the overall failure surface, organizations can build highly resilient networks that are easy to maintain, scale, and secure over time.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the practical differences between SLAs, SLOs, and SLIs is crucial for managing operational expectations across an enterprise. These three metrics connect technical performance directly to business agreements, ensuring that engineering teams and executives stay aligned.
- SLI (Service Level Indicator): The actual, real-time measurement of a system’s performance at any given moment. For example, a team might track an SLI showing that the network’s current error rate is exactly 0.02%.
- SLO (Service Level Objective): The internal target performance goal that the engineering team agrees to maintain over a set period. An example of an SLO is keeping the overall system error rate below 0.1% every month.
- SLA (Service Level Agreement): The overarching legal contract that defines what happens if the system fails to meet its promised reliability targets. These agreements often require companies to issue financial credits or penalties to clients if the SLO is missed.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of downtime or performance degradation that a system can safely tolerate over a specific month. Calculated directly from your internal SLO, it defines the clear mathematical boundary between acceptable system risk and unacceptable failure. For example, if your team maintains a 99.9% uptime objective, your monthly error budget allows for exactly 43 minutes of total downtime.
Total Monthly Time (100%)
┌─────────────────────────────────────────────────────────────┬──────────┐
│ Available Uptime Target defined by SLO (99.9%) │ Budget │
│ "Time dedicated to maintaining high system stability" │ (0.1%) │
└─────────────────────────────────────────────────────────────┴──────────┘
│
┌───────────────────────────┴────────────┐
▼ ▼
[Feature Deployments] [Unplanned Outages]
"Spent when pushing innovations" "Spent during downtime"
This concept completely removes emotional friction between product developers who want to ship code fast and operations engineers who prioritize stability. When the error budget is full and healthy, developers can confidently push innovative features and updates to production. However, if a series of unexpected outages completely drains the error budget, the team must immediately pause new feature releases. They shift 100% of their engineering focus toward fixing bugs, stabilizing the network, and rebuilding structural resilience.
Toil — The Silent Productivity Killer in Infrastructure
Toil is the operational work that tends to expand naturally as systems grow, unless engineers actively write software to eliminate it. It is defined as administrative, repetitive tasks that require manual execution, lack long-term creative engineering, and scale linearly with infrastructure size. If managing ten servers requires two hours of manual log cleaning per week, managing one thousand servers would demand an impossible amount of manual labor.
To systematically eliminate toil, engineering teams must first identify it by tracking how they spend their daily working hours. Once they pinpoint repetitive tasks, engineers design automated script daemons and self-healing control loops to handle the work programmatically. Eliminating this manual burden frees up talented engineers to focus on proactive architecture design, scalability improvements, and long-term network security updates.
Incident Management & Postmortems
When unexpected outages occur, structured incident management frameworks guide engineering teams to restore normal service operations as quickly as possible. This process requires defining clear operational roles, such as appointing an incident commander to coordinate response efforts and streamline internal communications. Once the system is stable, the team shifts their focus toward writing a comprehensive, blameless postmortem document.
A blameless postmortem culture assumes that engineers always act with good intentions based on the information they have at the time. Instead of pointing fingers at human operators, the review focuses on identifying the systemic flaws, missing alerts, or brittle code paths that allowed the failure to occur. The final document outlines concrete, time-bound engineering tasks to upgrade the infrastructure and prevent identical incidents from happening again.
Capacity Planning
Capacity planning is the practice of analyzing current systemic resource trends to ensure that infrastructure remains available ahead of future business growth. Without proactive planning, unexpected spikes in user activity can quickly overwhelm network bandwidth, deplete server memory, and cause widespread outages. Therefore, operations engineers track long-term data trends to forecast exactly when the organization will need additional hardware or cloud resources.
Modern capacity planning uses regular load-testing exercises to simulate heavy user traffic and find hidden breaking points in the network architecture. This data helps teams optimize resource allocations, negotiate better cloud pricing, and set up automated auto-scaling rules that handle seasonal traffic spikes smoothly. Planning ahead ensures that the platform delivers a fast, seamless experience for users, even during massive, unexpected traffic surges.
The Four Golden Signals of Pipeline Performance
To maintain complete visibility into infrastructure health, operations engineers focus heavily on tracking the Four Golden Signals of performance. Monitoring these four foundational metrics allows teams to quickly diagnose systemic issues, isolate bottlenecks, and optimize resource distribution across distributed environments.
- Latency: The total time it takes for a system to process a specific request and send a response back to the user. Engineers carefully track the differences in latency between successful requests and failed operations to find hidden code bugs.
- Traffic: A direct measurement of the total demand being placed on the network, such as HTTP requests per second or network bandwidth usage. Tracking traffic trends helps teams understand normal usage patterns and spot abnormal spikes caused by malicious security threats.
- Errors: The total rate of requests that fail to process successfully, split into explicit infrastructure errors and implicit data payload issues. A sudden spike in error rates usually indicates broken deployments, database disconnects, or misconfigured network routing rules.
- Saturation: A metric that shows how close a specific system resource is to reaching its maximum operating capacity limit. Tracking saturation across server memory, disk storage, and database connection pools allows teams to scale up resources before the platform slows down.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Understanding the distinction between high-level cultural frameworks and concrete technical implementations is essential for building a modern engineering organization. Cultural philosophies focus on breaking down operational silos, encouraging open communication, and fostering shared responsibility for system reliability across the entire business. These frameworks inspire teams to embrace automated workflows, accept calculated systemic risks, and learn from production failures without pointing fingers.
In contrast, platform implementation translates these cultural ideas into practical engineering realities within production environments. This technical discipline involves writing concrete automation scripts, setting up monitoring agents, configuring container orchestration tools, and managing infrastructure-as-code files. While culture provides the core values and alignment, platform implementation delivers the actual tools and code frameworks required to keep enterprise environments running reliably.
Roles & Responsibilities Compared
While both disciplines collaborate closely to maintain high system availability, their daily operational focuses and engineering priorities differ significantly. The following breakdown outlines how these roles distribute responsibilities across modern technology organizations.
- Cultural Operations Frameworks
- Focus heavily on driving collaboration, alignment, and shared business goals between distinct development and infrastructure teams.
- Prioritize expanding deployment frequency, accelerating overall time-to-market metrics, and optimizing the software delivery pipeline.
- Manage cultural adoption patterns, evaluate team communication loops, and champion automated practices across the wider organization.
- Measure long-term organizational success by tracking deployment velocity, cycle times, and the speed of software feature delivery.
- Platform Implementation Practices
- Focus deeply on maximizing infrastructure availability, building system resilience, and optimizing network performance targets.
- Prioritize reducing system error rates, managing error budgets, and conducting structural root-cause analysis during major outages.
- Manage concrete cloud architectures, build automated monitoring infrastructure, and write self-healing system deployment scripts.
- Measure day-to-day engineering success by tracking Mean Time to Resolution (MTTR), service uptime, and latency benchmarks.
Can You Have Both Disciplines?
Modern enterprises do not treat these two operational approaches as mutually exclusive choices; instead, they integrate them to create a high-performing engineering culture. Cultural alignment ensures that developers and operations engineers communicate openly, share metrics, and work toward the same business goals. At the same time, platform implementation provides the technical automation, alerting tools, and resilience patterns required to execute that shared vision safely.
When these two philosophies coexist effectively, they create a powerful operational feedback loop that drives sustainable business growth. Cultural maturity encourages teams to honestly analyze production failures, while platform engineering delivers the automated tools to fix those vulnerabilities permanently. Combining human-centric culture with technical execution allows organizations to ship features quickly without sacrificing the stability of their core networks.
Which One Should Your Team Adopt?
Choosing where to focus your engineering resources depends heavily on your organization’s current size, technical maturity, and operational bottlenecks. Small, early-stage startups should prioritize adopting a collaborative culture first, ensuring that their few engineers share deployment and monitoring responsibilities. At this stage, teams can use managed cloud services to keep operations simple and avoid building complex, custom internal platforms too early.
As an organization expands into a large enterprise with hundreds of microservices, investing heavily in dedicated platform implementation becomes absolutely necessary. Large environments require specialized engineering teams to manage complex container clusters, build internal developer portals, and enforce automated compliance policies. Balancing cultural health with advanced technical execution ensures that your infrastructure scales smoothly as your user base grows.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Global technology companies manage millions of concurrent user sessions by tracking real-time operational metrics across thousands of distributed servers. These enterprises use advanced telemetry pipelines to collect billions of performance data points every single day. By feeding this data into centralized visualization dashboards, engineering teams can monitor the exact health of global user transactions instantly.
These metrics allow companies to implement automated traffic routing, steering user requests away from degraded regional data centers automatically. For instance, if a network link between major regions experiences latency spikes, the edge load balancers redistribute workloads within milliseconds. This data-driven approach removes human guesswork from capacity management, keeping applications fast and responsive under heavy global demand.
Chaos Engineering Approaches to Resilient Systems
Leading streaming media platforms maintain high availability by intentionally injecting controlled failures into their production networks. This practice, known as chaos engineering, helps teams find hidden architectural flaws before they cause unexpected customer outages. Engineers use automated tools to randomly shut down microservices, disconnect databases, and simulate severe network latency in live environments.
[Chaos Engineering Tool] ➔ (Injects Random Node Failure in Live Production)
│
┌──────────────────────────┴──────────────────────────┐
▼ (Resilient System Design) ▼ (Brittle System Design)
[Auto-Healing Triggers] [Cascading Outage]
[Traffic rerouted to healthy nodes instantly] [Alerts fire; requires manual fix]
[Result: Zero customer impact] [Result: Hidden vulnerability exposed]
By intentionally breaking their own infrastructure during regular working hours, teams can verify that their self-healing systems function correctly. If an infrastructure failure causes a cascading outage, engineers can quickly isolate the issue and fix the underlying system code. This proactive experimentation builds deep confidence in the network’s ability to survive real-world hardware failures without disrupting users.
Handling Reliability at Massive Scale
Modern e-commerce enterprises handle massive traffic surges during global holiday shopping events by using highly distributed microservice architectures. These complex environments use smart load balancing, edge caching, and database replication to process tens of thousands of orders per second. To stay stable under these intense workloads, the infrastructure must scale compute resources up or down dynamically in response to real-time demand.
Operations engineers prepare for these events by running extensive end-to-end load tests months in advance to locate system limitations. They configure automated rate-limiting policies that protect core checkout systems from getting overwhelmed by non-essential background traffic. This disciplined focus on horizontal scalability ensures that the digital shopping platform remains fully operational when user traffic hits record highs.
High-Availability in Fintech Operations
Financial technology platforms and payment networks operate with a strict zero-tolerance policy for data loss and system downtime. A single minute of network unavailability can block millions of banking transactions, causing severe regulatory penalties and immediate financial loss. Therefore, fintech infrastructure relies on multi-region synchronous data replication and fully redundant network paths to protect system integrity.
Engineers design these banking networks with automated failover mechanisms that shift transactions to backup data centers instantly if a primary node drops. They also implement real-time fraud detection pipelines that analyze security telemetry data without slowing down user transaction speeds. This intense focus on high availability ensures that critical payment gateways stay secure and operational 24 hours a day, 365 days a year.
Scaled-Down but Essential Systems for Startups
Early-stage technology startups can apply these core operational principles efficiently without needing the massive infrastructure budgets of giant enterprises. Instead of building custom internal tooling, smart startups use managed cloud providers, automated serverless functions, and turnkey monitoring platforms. This lean setup allows small teams to automate their software deployment pipelines and track essential performance metrics with very little operational overhead.
Startups focus their limited time on setting up basic, high-impact alerts for critical errors, system latency, and resource saturation. By establishing clean infrastructure-as-code habits early, they ensure their software environments can scale up smoothly as their customer base grows. Implementing these foundational reliability habits early protects early-stage companies from operational chaos, letting them focus on launching new product innovations.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
Many traditional companies make the mistake of treating their operations engineering team as a reactive help desk that only wakes up to fix broken servers. When engineers spend 100% of their time firefighting alerts and manually restarting crashed applications, they have zero time left to fix the underlying system flaws. This reactive pattern traps organizations in a continuous loop of infrastructure instability and operational stress.
Modern operations engineering is fundamentally about proactive software engineering, not just answering pages and managing emergency bridge lines. Teams must have dedicated time to write automation scripts, design self-healing control loops, and optimize long-term network architecture. Shifting the focus from reactive firefighting to proactive engineering stops outages before they start, ensuring a highly stable production environment.
Mistake 2 — Setting Unrealistic SLOs
Product managers and executives often make the mistake of demanding perfect 100% uptime for their applications without considering the engineering costs. Setting unrealistic SLOs forces teams to build overly complex, expensive architectures that deliver minimal real-world value to customers. Furthermore, chasing perfect uptime completely stops feature innovation, as engineers become terrified of making any production updates that might cause a minor glitch.
Target Reliability Level
┌───────────────────────────────────────┬────────────────────────────────────────┐
│ Realistic SLO Target (99.9% Uptime) │ Unrealistic SLO Target (100% Uptime) │
├───────────────────────────────────────┼────────────────────────────────────────┤
│ • Allows 43 minutes of safe monthly │ • Permits zero downtime; highly │
│ downtime for upgrades. │ stressed engineering environment. │
│ • Promotes steady feature innovation │ • Halts product updates; engineers │
│ and code updates. │ become terrified of change. │
│ • Balances infrastructure costs │ • Drives up operational expenses with │
│ with customer satisfaction. │ diminishing returns. │
└───────────────────────────────────────┴────────────────────────────────────────┘
Teams must set realistic stability targets based on actual user expectations and clear business requirements. If a internal microservice can be down for ten minutes without affecting the customer experience, its SLO should reflect that flexibility. Embracing a realistic error budget allows organizations to balance platform safety with rapid feature deployment, keeping the engineering team fast and productive.
Mistake 3 — Ignoring Toil Until It’s Too Late
When engineering organizations scale up their user base without automating routine infrastructure work, they accumulate massive amounts of operational debt. Manual server setups, repetitive patch management, and hands-on database cleanups quickly multiply as more infrastructure nodes are added. Eventually, this mountain of repetitive toil consumes the team’s entire working week, leaving no time for valuable engineering upgrades.
[System Scale Increases] ➔ [Manual Toil Expands Linearly] ➔ [Engineering Time Shrinks to 0%]
│
┌──────────────────────────────────────────────┴──────────────────────────────┐
▼ ▼
[Severe Operational Debt] [Talented Engineers Burn Out]
[System updates stall completely] [Team leaves due to frustration]
To prevent this productivity drain, engineering leadership must track, measure, and cap manual toil strictly within their teams. When a repetitive operational task starts happening regularly, engineers should have the authority to pause routine work and automate it away. Prioritizing automation keeps the engineering team efficient, prevents human configuration errors, and allows infrastructure to scale smoothly without requiring a linear increase in headcount.
Mistake 4 — Skipping Blameless Postmortems
When a major system outage occurs, organizations often default to a toxic culture of blame, searching for the specific human operator who made the mistake. Punishing an engineer for typing a wrong command causes the entire team to hide mistakes, cover up system failures, and avoid sharing critical performance data. Consequently, the true systemic flaws remain completely unfixed, leaving the network vulnerable to the exact same outage in the future.
Progressive technology teams prevent this risk by making comprehensive, blameless postmortems a mandatory step after every single incident. By focusing the investigation entirely on broken engineering processes, missing monitoring metrics, and brittle code paths, teams discover why the system allowed the human mistake to happen. This transparent, educational approach turns every production failure into a valuable learning opportunity that strengthens the entire infrastructure.
Mistake 5 — Monitoring Without Actionable Alerts
A common pitfall in infrastructure management is configuring monitoring systems to send notifications for every single minor event or non-critical system fluctuation. When engineers receive dozens of non-urgent emails and phone notifications every day, they quickly develop severe alert fatigue. Consequently, when a critical, high-priority database failure actually occurs, the urgent alert gets buried in the noise and ignored by the tired team.
Every alert generated by your monitoring tools must be fully actionable and indicate a real, user-facing problem that requires immediate human intervention. Non-critical issues, like a single server disk reaching 80% capacity, should be logged quietly or handled automatically by automated cleanup scripts. Reserving urgent pages for true systemic emergencies reduces engineering burnout and ensures that critical issues get resolved before they impact users.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Software development teams frequently design new application features and complex data pipelines without consulting their operations engineering peers. When developers hand over finished software code to operations at the last minute, the infrastructure team often inherits an unstable, unscalable application that is incredibly difficult to monitor in production. This clear separation between teams leads to failed product launches, poor network performance, and continuous emergency deployments.
Operational specialists must be actively involved in the system architectural design process from day one of the project. Their deep experience with network routing, load testing, and cloud scalability helps software developers write highly resilient, production-ready code. Building operational requirements directly into the early design phase makes systems much easier to monitor, maintain, and scale efficiently over time.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Maintaining complete control over modern distributed networks requires a powerful suite of integrated monitoring and observability tools. These technologies work together to ingest high-velocity telemetry data, trace system requests, and visualize real-time infrastructure performance across hybrid environments.
| Tooling Class | Common Industry Solutions | Primary Operational Value |
| Time-Series Metrics | Prometheus, InfluxDB | Ingests and stores high-velocity system metrics for real-time alerting. |
| Data Visualization | Grafana | Synthesizes complex multi-source telemetry data into clear, scannable dashboards. |
| Enterprise Observability | Datadog, New Relic | Provides end-to-end request tracing, log aggregation, and APM visualization. |
Incident Management
When critical network systems experience unexpected degradation, incident management platforms coordinate emergency engineering responses to minimize total downtime. These automated systems parse real-time alerts from monitoring tools, identify which engineers are on-call, and route urgent notifications through phone calls, SMS, and chat applications. Platforms like PagerDuty and Opsgenie help teams track incident resolution times, organize emergency conference bridges, and manage automated escalation paths if the primary engineer is unreachable. By streamlining internal team communications during high-stress outages, these tools help organizations reduce their Mean Time to Resolution (MTTR) significantly.
CI/CD & Release Engineering
Continuous Integration and Continuous Deployment (CI/CD) engines form the foundational backbone of modern automated release engineering practices. These automation tools automatically compile software code, execute validation tests, and deploy infrastructure changes across production environments based on version control updates. Standard platforms like Jenkins, Gitlab CI, and advanced cloud-native tools like Argo CD or Spinnaker allow engineers to build safe, predictable release patterns. By utilizing automated canary deployments and blue-green rollout strategies, these platforms ensure that software updates roll out smoothly with zero user disruption.
Chaos Engineering
Chaos engineering tools allow infrastructure specialists to test system resilience proactively by injecting controlled failures directly into live production environments. Advanced tools like Chaos Monkey, Gremlin, and LitmusChaos automatically terminate virtual servers, simulate severe network latency, and disrupt cloud storage connections according to pre-defined experiments. These controlled disruptions help engineering teams discover hidden single points of failure, validate auto-scaling triggers, and test that monitoring alerts fire correctly under stress. Running regular chaos simulations helps enterprises transform theoretical system reliability into proven, operational resilience.
SLO Management
Dedicated Service Level Objective (SLO) management tools help modern enterprises track long-term reliability metrics against agreed user thresholds. Platforms like Nobl9 and open-source SLO frameworks connect directly to time-series databases to calculate error budgets and performance trends automatically. These specialized systems provide product managers and infrastructure engineers with clear visibility into how much error budget remains available for new feature releases. By automating error budget alerts, these platforms notify teams when performance drops threaten to violate external customer contracts, helping businesses balance innovation with system safety.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Building a successful career in modern operations engineering requires a balanced mix of system administration knowledge, cloud architecture design, and software development skills. Aspiring specialists must start by mastering the Linux command-line terminal, including shell scripting, file system management, and process isolation techniques. Understanding these fundamental operating system concepts allows engineers to troubleshoot low-level application performance issues and automate routine server maintenance tasks efficiently.
[Linux Command Line & Scripting] ➔ [Networking Protocols & Security] ➔ [Cloud Infrastructure & IaC]
Additionally, professionals need a deep, practical understanding of networking protocols, including TCP/IP routing, DNS resolution, and SSL/TLS certificate configurations. You must also learn how to manage infrastructure programmatically using modern scripting languages like Python or Go, alongside cloud-native tools like Terraform. These technical skills allow operations engineers to build scalable, secure, and self-healing environments across major public cloud platforms.
The Professional Learning Path
The educational path to becoming a senior infrastructure architect begins with building a strong foundation in basic software development and local system configuration. Beginners should focus on packaging applications inside Docker containers and learning how to deploy simple web apps onto cloud networks manually. Once you master basic setups, the next step is learning container orchestration using Kubernetes, alongside automated CI/CD deployment pipelines.
As engineers move into intermediate roles, they focus heavily on mastering observability principles, configuring telemetry pipelines, and defining clear SLO metrics. Senior architecture specialists spend their time designing global multi-region cloud networks, optimizing database replication strategies, and building automated disaster recovery frameworks. This gradual progression ensures that professionals develop the deep engineering intuition required to manage massive, high-traffic enterprise infrastructures safely.
Certifications Worth Pursuing
While real-world engineering experience remains invaluable, earning respected, industry-recognized certifications can validate your technical expertise and accelerate your career growth. Professionals should look toward cloud-native credentials, such as the Certified Kubernetes Administrator (CKA) or the Certified Kubernetes Application Developer (CKAD). These practical, hands-on exams prove to global employers that you can configure, secure, and troubleshoot complex containerized clusters under real-world conditions.
Furthermore, earning advanced certifications from major cloud providers—like the AWS Certified DevOps Engineer Professional or the Google Cloud Professional Cloud DevOps Engineer—adds significant market value. These enterprise credentials validate your ability to design automated deployment pipelines, optimize cloud spend, and implement high-availability architectures at scale. Focusing on performance-based, hands-on certifications ensures that your credentials reflect genuine, practical engineering capability.
Educational Resources with Noopsschool
Aspiring specialists can accelerate their professional journey by exploring the deep-dive training programs and hands-on laboratory courses provided by Noopsschool. These comprehensive educational tracks focus on real-world engineering scenarios, moving far beyond basic academic theory to teach actual production troubleshooting. Students gain access to simulated live infrastructure environments where they can practice configuring large Kubernetes clusters, setting up observability dashboards, and managing enterprise networks.
Noopsschool provides structured learning paths tailored for both beginner administrators looking to enter the field and senior developers shifting toward platform reliability roles. The courses are continuously updated by active industry experts to reflect the latest automation tools, security standards, and architectural best practices. Investing your time in these high-quality, practical training modules ensures you build the concrete skills required to manage modern enterprise systems.
The Future of Systems Management
AI and Automation in System Optimization
Artificial intelligence and machine learning models are fundamentally changing how modern enterprises monitor, tune, and protect their network infrastructure. Future operations systems use predictive analytics engines to scan terabytes of live telemetry data and identify subtle performance anomalies before they turn into major outages. These smart systems can automatically isolate failing microservices, adjust load balancer weights, and scale up computing capacity in response to real-time traffic shifts.
Additionally, AI assistants are accelerating incident response efforts by automating root-cause analysis and suggesting proven code fixes to on-call engineers during emergencies. Machine learning algorithms can also analyze historical resource usage trends to optimize database caching strategies and adjust cloud configurations automatically. This integration of intelligence into automation allows infrastructure teams to transition from reactive troubleshooting to fully predictive system management.
Platform Engineering — The Evolution of Infrastructure
Platform engineering is quickly becoming the dominant operational pattern for scaling software delivery across modern, fast-growing technology enterprises. This discipline focuses on building Internal Developer Platforms (IDPs) that package complex cloud infrastructures, automated deployment tools, and security guardrails into self-service portals. By providing software developers with easy, turnkey access to pre-approved cloud environments, companies can eliminate manual ticketing delays entirely.
[Software Developer] ➔ [Self-Service Internal Developer Portal (IDP)]
│
┌──────────────────────────┴──────────────────────────┐
▼ (Automated Platform Engineering Guardrails) ▼
[Instant App Environment Provisioned] [Security & Budget Limits Enforced]
[CI/CD pipelines created automatically] [Compliance tracking active instantly]
This evolution allows operations specialists to stop managing individual server requests and focus on building scalable, reusable infrastructure templates. Platform engineering establishes clear operational standards across the entire business, ensuring that every deployment automatically follows security, budget, and logging compliance rules. This shift accelerates product delivery timelines while maintaining high system stability and governance across the company.
Management in Cloud-Native & Kubernetes Environments
As enterprises continue migrating their core business workloads onto distributed container clusters, managing complex Kubernetes environments requires highly specialized operational strategies. Modern cloud-native architectures use advanced service mesh technologies to secure network communication, manage data traffic, and trace requests across thousands of individual containers. Operations engineers must design dynamic routing rules that accommodate short-lived server nodes that launch and terminate continuously throughout the day.
[Incoming Global User Traffic]
│
▼
[Ingress Controller]
│
┌──────────┴──────────┐
▼ ▼
[Pod Alpha (Node 1)] [Pod Beta (Node 2)] ◄── (Dynamic Service Mesh Routing)
│ │
└──────────┬──────────┘
▼
[Auto-Scaling Trigger] ➔ [Launches Pod Gamma (Node 3) Instantly]
Managing infrastructure at this scale requires using declarative, GitOps-driven automation workflows, where git repositories serve as the single source of truth for the entire environment. Automated synchronization engines continuously monitor cluster configurations, automatically correcting any manual changes to match the approved git state. This disciplined cloud-native approach ensures that large distributed networks remain predictable, easy to audit, and highly resilient against unexpected hardware failures.
Operational Skills That Will Matter Most
The future demands that systems management specialists expand their skill sets beyond basic server configuration and script writing to embrace broader business disciplines. As corporate cloud computing budgets expand globally, mastering FinOps—the practice of combining financial accountability with cloud optimization—is becoming a critical requirement for senior engineers. Professionals must learn to design efficient, cost-optimized architectures that scale compute resources down dynamically during low-traffic hours to eliminate waste.
Furthermore, future engineering roles require a deep expertise in advanced data observability, structured log analytics, and distributed application tracing methods. Operations specialists must also build strong communication skills to lead blameless team postmortems and align engineering goals with high-level business objectives. Cultivating this blend of deep technical skill, financial discipline, and collaborative leadership ensures that you remain a highly valuable infrastructure asset.
FAQ Section
- What is the difference between network operations and platform engineering?
Network operations focuses primarily on maintaining the immediate reliability, uptime, and traffic performance of active production systems and data pipelines. In contrast, platform engineering builds the underlying self-service internal developer portals, automated tooling, and infrastructure templates that developers use to deploy applications independently.
- How do engineering teams calculate and use an error budget effectively?
Teams calculate an error budget by subtracting their internal Service Level Objective (SLO) percentage from a perfect 100%. The remaining fraction represents the acceptable downtime allowed each month for shipping innovative features; if the budget drains completely, developers must pause updates and focus entirely on infrastructure stability.
- What entry-level skills are most critical for starting a career in this field?
Aspiring specialists must focus on mastering the Linux command line terminal, learning foundational networking protocols like DNS and TCP/IP, and writing automation scripts in Python or Go. Understanding how to build application containers using Docker and manage infrastructure using basic Terraform code is also essential for modern roles.
- Why are blameless postmortems considered so vital for long-term reliability?
Blameless postmortems focus on finding broken technical processes, missing alerts, and brittle code paths rather than punishing individual human operators for making mistakes. This transparent culture encourages engineers to share performance data honestly, turning production failures into valuable lessons that strengthen the system against future outages.
- What are the typical salary trends for systems infrastructure experts?
Salaries for infrastructure specialists remain highly competitive globally due to the critical business need for continuous platform uptime and scalable cloud management. Experienced platform architects and reliability engineers frequently earn premium compensation packages that match or exceed those of senior software developers across major technology hubs.
- How does automated capacity planning protect companies from sudden traffic spikes?
Automated capacity planning analyzes long-term performance telemetry and runs regular high-volume load tests to find hidden bottlenecks before they cause downtime. This data allows teams to configure smart auto-scaling policies that provision additional cloud resources instantly when traffic surges, keeping the application fast and reliable.
Final Summary
Maintaining clean, observable, and highly automated network environments is absolutely essential for scaling modern enterprise software platforms securely. By embracing data-driven Service Level Objectives, eliminating manual toil, and fostering a collaborative, blameless engineering culture, organizations protect their digital services from catastrophic downtime. Implementing these structured operations practices transforms fragile infrastructure into highly resilient, self-healing networks capable of surviving real-world hardware failures. To stay ahead of shifting deployment patterns and master these critical architecture skills, engineering teams can explore the expert training programs and professional resources available at Noopsschool to build a reliable future.