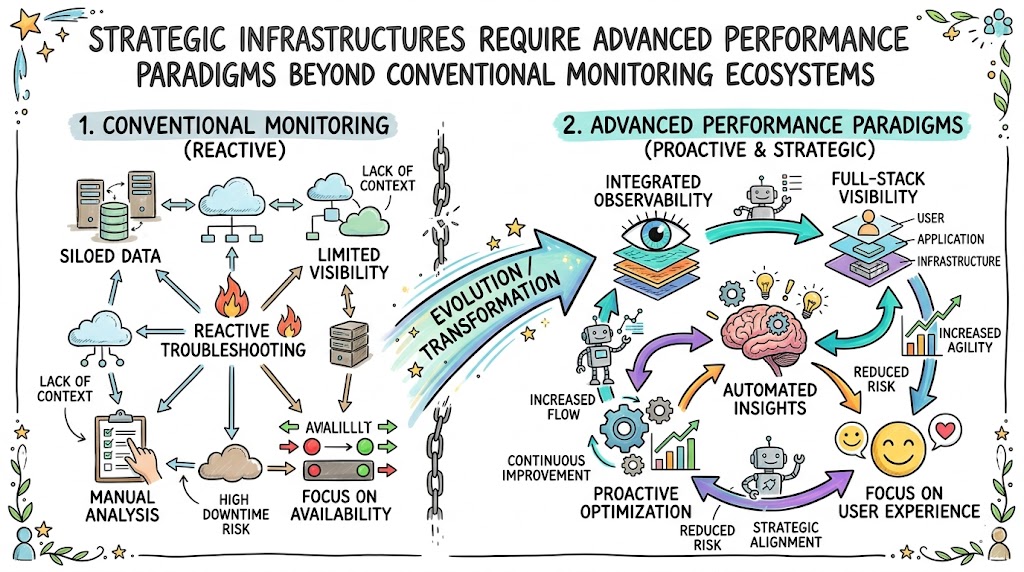
Imagine a sudden database disruption freezing transactional pipelines across three continents simultaneously. The localized engineering infrastructure fragments while support queues surge with thousands of real-time alerts. Siloed monitoring software platforms display conflicting diagnostics, leaving cross-functional operators blind to the core systemic failure. This operational bottleneck highlights the deep vulnerabilities within legacy network coordination paradigms. High-velocity enterprises require integrated frameworks capable of unifying telemetric observations with autonomous, continuous stabilization to survive massive load variations (Liu et al., 2024).
Modern technological ecosystems utilize advanced software-defined infrastructure to transform physical infrastructure into programmable assets (Liu et al., 2024). This structural movement unifies system administration with software development principles, ensuring services achieve high availability through programmatic orchestration. This comprehensive guide details the foundational architectures, operational workflows, and advanced reliability practices essential for running massive systems. Engineering leaders must move past simple reactive incident handling to build autonomous, data-driven platforms. Discover how specialized educational pathways at Noopsschool provide the technical training and structural expertise needed to lead these modern platform transformations.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise data ecosystems relied completely on manual system configuration and static hardware provisioning. Development departments operated entirely apart from infrastructure deployment teams, creating a major barrier to delivery velocity. When production networks suffered severe capacity overloads, structural analysis devolved into defensive blame shifting between siloed units. System updates required prolonged physical maintenance windows, which routinely introduced human configuration errors and forced sudden rolling rollbacks.
Moving Toward Unified Workflow Automation
The introduction of virtualization and software-defined architectures redefined infrastructure provisioning by turning bare hardware into modular, code-driven software resources (Liu et al., 2024). Corporate environments started adopting unified orchestration patterns, allowing automated continuous integration pipelines to deploy changes directly to target systems. This integration helped teams break down functional barriers, align metrics, and coordinate operations continuously. Programmatic automation eliminated manual server configuration, allowing modern enterprises to deploy updates reliably dozens of times each day.
Global Expansion Across Commercial Ecosystems
As cloud architectures expanded internationally, large enterprise architectures faced severe scaling challenges across widely distributed multi-region facilities. Simple localized scripts could no longer manage thousands of concurrent server clusters running millions of processes. Global organizations recognized that systemic reliability required formal architectural patterns, which turned manual maintenance into reproducible software templates. This operational framework spread through global markets, establishing high-availability engineering as a foundational component for modern, high-growth technology companies.
Defining Strategic Operations Management
The Core Operational Structure
Advanced infrastructure management relies on a continuous feedback architecture that bridges physical systems, telemetry pipelines, and orchestrators. Raw application logs, trace paths, and edge hardware metrics flow seamlessly into unified telemetry databases (Li, 2026). Automated policy compilers process this data stream in real time to compare actual operational performance with target reliability levels. When anomalies appear, the orchestration layer triggers self-healing tasks, balancing dynamic traffic demands across computing zones without requiring manual configuration.
Daily Tasks of Systems Coordinators
Systems specialists focus on optimizing pipeline throughput while reducing repetitive manual upkeep. They spend their workdays building robust code templates for infrastructure delivery, writing self-healing scripts for systems, and polishing data collection frameworks. These engineers also review architectural anomalies, adjust alerting thresholds to prevent notification fatigue, and lead blameless retrospective evaluations after major outages. By keeping a strict balance between feature support and systems engineering, teams protect the long-term health of their delivery environments.
Localized Control vs. Broad System Architecture
Managing micro-level elements requires tracking individual container runtimes, granular processor schedules, and specific memory usage parameters. In contrast, managing macro-level architecture focuses on regulating traffic profiles across distributed cloud zones and ensuring smooth inter-service data delivery. While micro-level tracking helps isolate specific bugs, macro-level coordination gives visibility into complex structural dependencies. Modern production environments require balancing both perspectives to prevent local hardware glitches from cascading into global system outages.
The Efficiency Mindset
Achieving high reliability requires shifting team culture away from quick patch fixes toward building long-term systemic stability. Engineers treat operational failures as valuable diagnostic feedback about hidden gaps in software logic or infrastructure design. This philosophy prioritizes proactive system resilience, ensuring teams invest continuous effort into automated testing, error mitigation, and infrastructure documentation. Designing clean, simplified architectures from the start allows enterprises to handle massive scaling pressure while minimizing ongoing operational overhead.
The 7 Core Principles of Network Operations
┌─────────────────────────────────────────────────────────┐
│ 1. Embrace Risk & Manage Variability │
└────────────────────────────┬────────────────────────────┘
│
┌────────────────────────────▼────────────────────────────┐
│ 2. Establish Measurable SLOs │
└────────────────────────────┬────────────────────────────┘
│
┌────────────────────────────▼────────────────────────────┐
│ 3. Eliminate Toil via Automation │
└────────────────────────────┬────────────────────────────┘
│
┌────────────────────────────▼────────────────────────────┐
│ 4. Maintain Continuous Observability │
└────────────────────────────┬────────────────────────────┘
│
┌────────────────────────────▼────────────────────────────┐
│ 5. Scale via Programmatic Code │
└────────────────────────────┬────────────────────────────┘
│
┌────────────────────────────▼────────────────────────────┐
│ 6. Ensure Predictable Deployments │
└────────────────────────────┬────────────────────────────┘
│
┌────────────────────────────▼────────────────────────────┐
│ 7. Enforce Simplicity in Architecture │
└────────────────────────────╚────────────────────────────╝
1. Embracing Risk and Managing Variability
Attempting to maintain complete, uninterrupted runtime perfection is inherently counterproductive and hinders delivery velocity. Modern systems operate on the principle that hardware components will fail unexpectedly, network packets will drop, and cloud resources will fluctuate. Teams calculate acceptable risk parameters to balance service reliability against the speed of rolling out new features. Embracing minor, controlled systemic variations allows organizations to innovate rapidly while protecting baseline system performance.
2. Establishing Service Level Objectives (SLOs)
Reliability must be defined using clear, mathematical metrics that match the actual experience of end users. Teams establish strict quantitative targets for specific indicators like system latency, request success percentages, and data throughput. These operational objectives keep development priorities aligned with infrastructure requirements, providing data-driven guidance on when to release features or focus on architectural stability.
3. Eliminating Toil and Manual Processes
Repetitive, non-creative manual tasks that offer no long-term structural value can stall engineering momentum and create operational risk. Teams track manual actions like manual server reboots, repetitive user access provisioning, and manual data patching to script them away permanently. Engineering out these repetitive tasks frees technical staff to spend their time designing resilient architectures and improving platform performance.
4. Monitoring & Observability Across the Pipeline
Maintaining deep visibility across all distributed applications helps engineering teams catch hidden software anomalies before they cause user-facing outages. Observability frameworks ingest real-time structured data paths, system performance logs, and deep execution traces to uncover hidden resource contentions. This unified visibility ensures teams can pinpoint the root cause of failures within complex microservices, eliminating guesswork during critical production incidents.
5. Automation Over Manual Coordination
Scaling modern, high-traffic tech platforms requires managing infrastructure exclusively through code rather than manual box-by-box configuration. Engineers use declarative scripts to provision, modify, and retire system components across distributed cloud networks. This programmatic approach ensures all deployment environments stay consistent, reduces human configuration mistakes, and lets platforms scale smoothly without increasing operational headcount.
6. Release Engineering and Deployment Stability
Delivering updates successfully requires building standardized, automated deployment pipelines that use rigorous validation checks. Production teams use reliable rollout patterns like blue-green environments or canary updates to safely test modifications on small slices of live traffic. Automated rollback loops continuously track error rates, instantly reversing deployments if performance numbers drop below agreed thresholds.
7. Simplicity in Network Architecture
Intricate, over-engineered networks create hidden dependencies that complicate incident resolution and mask root causes during outages. Systems engineers strive to keep data pathways straightforward, minimize component layers, and remove unneeded architectural dependencies. Prioritizing lean, understandable environments reduces the overall system failure surface and allows engineers to isolate and fix production bugs quickly.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
- Service Level Agreement (SLA): The formal commercial commitment made directly to external consumers, defining the financial penalties or credits applied if the service fails to meet reliability targets.
- Service Level Objective (SLO): The internal target metric used by engineering teams to keep system reliability safely above the public SLA threshold.
- Service Level Indicator (SLI): The specific, real-time quantitative measure of performance, like the percentage of successful API calls or latency under 200 milliseconds.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the acceptable amount of system downtime or performance degradation a service can experience over a set period. Calculated directly as $1 – \text{SLO}$, this metric serves as an objective operational gauge that controls release velocity. If a system maintains high stability and retains a healthy error budget, development teams can safely roll out high-risk software changes. However, if consecutive production incidents exhaust the allocated budget, the deployment pipeline locks automatically, forcing engineering teams to pivot resources entirely toward improving system stability.
Toil — The Silent Productivity Killer in Infrastructure
Toil defines the manual, repetitive administrative overhead that grows linearly with system scale and offers no long-term architectural benefits. Tasks like clearing full disk partitions manually, resetting user service passwords, and verifying server configurations by hand drain engineering capacity. Organizations calculate these manual footprints to ensure they do not consume more than half of an engineer’s time. Teams systematically eliminate these bottlenecks by writing automated cleanup scripts and building self-service access tools.
Incident Management & Postmortems
When severe production outages occur, engineering organizations launch structured incident response workflows using designated communication leads. Once the system is stabilized, cross-functional teams hold blameless retrospective meetings to analyze the underlying systemic gaps. These reviews assume that engineers act in good faith with the information available, focusing on fixing weak validation pipelines and improving alerting logic rather than assigning individual blame. Transforming operational incidents into clear, actionable engineering tickets prevents identical failures from happening again.
Capacity Planning
Predictive capacity planning ensures that large-scale technology platforms retain enough underlying hardware resources to handle sudden traffic surges without performance drops. Engineers analyze long-term telemetry trends, seasonal user behavior, and business growth forecasts to model future compute requirements. Teams use these models to automate hardware scaling patterns, run load tests on infrastructure limits, and balance resource costs against peak performance needs.
The Four Golden Signals of Pipeline Performance
- Latency: The total time required to process a specific request successfully, separating the delivery speeds of successful calls from failed transactions.
- Traffic: The overall volume of demand hitting the platform, measured in parameters like HTTP requests per second or network bandwidth consumption.
- Errors: The rate of requests failing across the platform, tracking both explicit application errors and slow, unexpected timeout drops.
- Saturation: The fraction of system resources that are fully utilized, highlighting hardware bottlenecks like constrained memory spaces or full disk arrays.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
High-level cultural frameworks focus on breaking down organizational silos, encouraging shared responsibility, and embracing continuous architectural experimentation. Technical platform implementations turn these cultural goals into concrete reality by providing the automated tooling, telemetry pipelines, and infrastructure controls needed for stable operation. Culture helps team mindsets align on shared objectives, while implementation gives engineers the practical code-driven mechanics to build, protect, and scale live systems.
Roles & Responsibilities Compared
- Cultural Facilitators: Focus on optimizing cross-team communication pathways, standardizing postmortem feedback loops, and ensuring clear alignment between business goals and engineering metrics.
- Systems Architects: Focus on writing declarative infrastructure templates, building automated canary deployment tracks, and scaling distributed telemetry clusters.
- Site Engineers: Spend their time creating self-healing scripts, tuning distributed databases for optimal throughput, and building self-service developer portals.
- Security Engineers: Focus on injecting automated compliance checks directly into active integration lines, managing system secrets securely, and conducting automated vulnerability scans across container networks.
Can You Have Both Disciplines?
Modern, high-performance technology organizations do not treat operational culture and technical infrastructure execution as opposing priorities. Instead, advanced engineering teams merge these areas, using automated tooling to enforce cultural goals like blameless tracking and shared metrics. For example, automated error budget enforcement turn abstract reliability goals into objective, code-driven release guardrails. Combining human-centric operational philosophies with automated platform design lets organizations scale rapidly while maintaining system stability.
Which One Should Your Team Adopt?
Choosing the right operational focus depends on your team’s current engineering maturity and the complexity of your technology stack.
Table 1: Operational Strategy Selection Matrix
| Organization Profile | Primary Architecture | Recommended Core Focus | Implementation Method |
| Early-stage startup with rapid prototyping needs | Monolithic cloud application instances | High-level cultural agility and shared responsibilities | Lightweight scripts, manual metric tracking, and rapid iteration |
| Mid-market enterprise expanding core systems | Transitioning to decoupled microservice architectures | Standardized technical platform automation tracks | Infrastructure as Code, central logging, and early SLOs |
| Large multinational technology institution | Global multi-cloud container orchestration frameworks | Full integration of cultural and advanced platforms | Automated error budget blocks and multi-region self-healing |
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Global streaming providers and e-commerce giants use real-time telemetry pipelines to track user interaction patterns across millions of active devices. These platforms process stream telemetry at the edge, using automated data engines to spot minor deviations in latency or regional drop rates. If data throughput falls below baseline levels in a specific region, routing architectures automatically shift user traffic to healthy data centers. This automated response isolates the underlying network issues without degrading the end-user experience.
Chaos Engineering Approaches to Resilient Systems
Enterprise engineering teams build resilient systems by intentionally injecting controlled failures into live production environments. Automated testing agents randomly terminate container clusters, drop network packets, or inject API latency during standard working hours. These experiments allow teams to verify that their self-healing systems and redundant databases automatically catch and mitigate real-world failures. Uncovering hidden system bugs through controlled testing ensures platforms can survive major, unexpected real-world blackouts.
Handling Reliability at Massive Scale
Distributed microservice platforms process millions of concurrent transactions by shifting traffic dynamically across independent, isolated infrastructure fault zones. When a specific backend service experiences an unexpected resource bottleneck, automated circuit breakers trip instantly to decouple that component. The platform handles the spike gracefully by serving cached data or simplified fallback screens to users, stopping local errors from cascading. This modular isolation keeps core payment pipelines stable even during major downstream dependencies failures.
High-Availability in Fintech Operations
Financial transaction networks require absolute zero-tolerance for transaction drops, data corruption, or connection latency spikes. These systems use multi-region database configurations that replicate transaction records across independent physical facilities instantly. Automated reconciliation engines validate every ledger entry in real-time, while dedicated networking channels protect communication between banking endpoints. This focus on deep redundancy ensures continuous operation and data integrity even during total datacenter power failures.
Scaled-Down but Essential Systems for Startups
Early-stage engineering teams use cloud-managed infrastructure services to apply core reliability principles without maintaining massive operations departments. Startups focus on setting up basic, foundational SLOs for core business features and tracking primary performance signals through consolidated dashboards. Automating simple rollback loops within their deployment lines protects their early systems from human configuration errors. This lean approach gives small teams the stable foundations needed to scale smoothly as their user base grows.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
Treating an operations engineering department as a reactive, 24/7 help desk tasked only with clearing alerts is a fundamental misuse of engineering capacity. When teams spend all their time fighting live production fires, they accumulate massive technical debt and cannot build long-term stability tools. Real operations work requires dedicated engineering time to build automated self-healing software and improve infrastructure design. Shifting the team’s focus from reactive fire-fighting to proactive automation is what separates resilient platforms from fragile systems.
Mistake 2 — Setting Unrealistic SLOs
Demanding complete, unyielding service uptime across all systems stalls product release cycles and burns out engineering talent. Perfection is an expensive, impractical goal; building infrastructure to guarantee zero downtime requires massive investments in redundant systems and complex configurations. These complex setups often make environments more difficult to troubleshoot when multi-variable bugs appear. Teams must set realistic reliability goals that protect user experience without blocking developer velocity.
Mistake 3 — Ignoring Toil Until It’s Too Late
Neglecting repetitive manual tasks in growing technical environments creates a hidden operational bottleneck that stalls product momentum. As infrastructure expands, manual tasks like provisioning user access and patching servers consume all available engineering hours. This lack of automation leaves technical teams with no time to design resilient systems, increasing the risk of configuration errors. Organizations must explicitly track and cap manual toil to keep their platforms agile and scalable.
Mistake 4 — Skipping Blameless Postmortems
When organizations penalize teams for technical failures, engineers hide configuration mistakes and minimize production incidents to avoid blame. Punishing individuals leaves the underlying broken automation pipelines, poor testing tracks, and confusing alert systems unfixed. True system resilience requires analyzing failures openly and identifying the root architectural gaps that allowed human error to reach production. Embracing a blameless engineering culture turns costly operational outages into clear, actionable system improvements.
Mistake 5 — Monitoring Without Actionable Alerts
Inundating engineering teams with non-actionable notification pings creates severe alert fatigue, leading engineers to miss critical production warnings. When monitoring systems trigger urgent pages for minor, self-correcting memory fluctuations, teams quickly learn to ignore systemic alerts. Alerts should only fire when a system is experiencing actual user-facing degradation that requires immediate human intervention. Every automated page must link to a clear troubleshooting document, ensuring engineers can diagnose and fix live failures quickly.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Isolating software application development teams from infrastructure engineers during initial system design results in fragile production deployments. Software built without operational input often lacks essential telemetry endpoints, struggles with scaling limits, and cannot fail gracefully during network drops. Bringing operations specialists into early design discussions ensures applications are built from day one to be observable, highly scalable, and resilient. Proactive architectural collaboration prevents costly, complex engineering re-writes after code hits live production environments.
Essential Infrastructure Tools & Technologies
┌────────────────────────────────────────────────────────────────────────┐
│ TEAMS & ROLES │
│ [DevOps / SRE] [Platform Engineers] [Systems Coordinators] │
└───────────────────────────────────┬────────────────────────────────────┘
│ Ingests Logs, Traces, & Metrics
▼
┌────────────────────────────────────────────────────────────────────────┐
│ OBSERVABILITY & TELEMETRY │
│ [Prometheus] [Grafana] [Datadog] [New Relic] │
└───────────────────────────────────┬────────────────────────────────────┘
│ Triggers Alerts & On-Call Routing
▼
┌────────────────────────────────────────────────────────────────────────┐
│ INCIDENT & RESILIENCE ENGINES │
│ [PagerDuty] [Nobl9] [Chaos Monkey] │
└───────────────────────────────────┬────────────────────────────────────┘
│ Drives Automated Release Loops
▼
┌────────────────────────────────────────────────────────────────────────┐
│ AUTOMATION & DELIVERY │
│ [Argo CD] [Spinnaker] [Jenkins] │
└────────────────────────────────────────────────────────────────────────┘
Monitoring & Observability
Maintaining deep visibility into multi-cloud environments requires a unified stack of real-time telemetry tools. Teams use Prometheus to collect fine-grained time-series metrics from containerized applications, while using Grafana to build consolidated dashboards. For large enterprise architectures, platforms like Datadog and New Relic combine log files, system metrics, and execution traces into a single view. These tools help engineers track performance baselines and identify hidden resource bottlenecks across distributed microservices.
Incident Management
When unexpected outages occur, automated platforms ensure response teams can coordinate rapidly to minimize customer impact. Services like PagerDuty ingest real-time alerts from telemetry pipelines, automatically route tickets to the correct on-call engineers, and manage escalation paths if issues persist. These tools establish clear communication lines, archive event timelines for postmortem reviews, and keep technical stakeholders aligned throughout the incident lifecycle.
CI/CD & Release Engineering
Modern software delivery relies on automated engines to test, pack, and deploy code changes safely across production clusters. Platforms like Jenkins manage initial continuous integration lines, running automated security scans and code validation suites on every update. For cloud-native environments, Spinnaker and Argo CD provide declarative continuous delivery, automatically shifting live traffic to new deployments and reversing updates if performance metrics drop.
Chaos Engineering
Engineers discover hidden architectural flaws by using specialized chaos testing frameworks to inject controlled failures into live networks. Tools like Chaos Monkey deliberately shut down production server instances, drop network routes, and trigger resource bottlenecks under close observation. Running these continuous resilience experiments helps teams verify that their systems automatically route around failures without manual intervention or user disruption.
SLO Management
Tracking real-time user experiences against corporate reliability commitments requires dedicated service level management software. Platforms like Nobl9 capture performance indicators from multiple telemetry engines to calculate real-time error budget consumption rates. These systems provide clear, data-driven visualization into long-term reliability trends, helping engineering leaders decide whether to prioritize new product features or invest in infrastructure stability.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Building a career in infrastructure engineering requires mastering core operating system internals, shell scripting languages, and software networking concepts. Aspiring engineers must be comfortable using the Linux command line to analyze running processes, inspect file systems, and debug network paths. Proficiency in languages like Python or Go is essential for writing infrastructure automation scripts and building custom telemetry integrations. Additionally, specialists must understand cloud infrastructure mechanics, including container configurations, security protocols, and distributed database routing patterns.
The Professional Learning Path
The path to becoming an expert starts with mastering basic system administration, local network setup, and manual server configuration. Next, engineers should learn Infrastructure as Code techniques to provision and manage cloud resources programmatically using structured configuration files. From there, technical professionals move into orchestration, learning to manage dynamic container environments across distributed clusters. Senior-level paths focus on designing resilient global system architectures, standardizing disaster recovery workflows, and balancing platform infrastructure costs against enterprise reliability targets.
Certifications Worth Pursuing
Industry-recognized certifications help engineers validate their technical infrastructure expertise and accelerate their career growth. The Certified Kubernetes Application Developer (CKAD) credential proves an engineer’s ability to deploy and configure applications inside containerized environments. Pursuing networking pathways like the Cisco Certified Network Associate (CCNA) validates a deep understanding of core data routing protocols and infrastructure design. For cloud foundations, earning credentials like Microsoft Azure Fundamentals highlights a strong grasp of scalable cloud architecture models and enterprise security frameworks.
Educational Resources with Noopsschool
Acquiring the hands-on experience needed to manage massive, high-traffic tech platforms requires structured, expert-led training. Educational platforms like Noopsschool offer comprehensive technical tracks designed to build deep real-world systems engineering capabilities. Students work through interactive lab environments that simulate real production outages, configure automated integration pipelines, and set up live cluster monitoring. Learning under the guidance of industry mentors prepares technical professionals to lead complex platform engineering transformations within enterprise organizations.
The Future of Systems Management
AI and Automation in System Optimization
The integration of machine learning frameworks into live monitoring pipelines is redefining how modern enterprises handle incident response and system maintenance. Automated anomaly detection models process millions of telemetry events in real-time, isolating the root causes of system failures before they trigger user-facing outages (Ardestani et al., 2025). Instead of sorting through long log files manually, on-call engineers receive auto-generated summaries that explain exactly which code change caused the issue. These intelligent platforms use closed-loop automation to scale system resources and reconfigure network paths dynamically, optimizing system health without human intervention (Bimo et al., 2025).
Platform Engineering — The Evolution of Infrastructure
Modern infrastructure management is shifting away from custom scripts toward building unified, self-service Internal Developer Platforms (IDPs). Platform engineering teams package complex cloud infrastructure, deployment pipelines, and compliance rules into simple, automated portals. Software developers use these portals to provision databases and spin up test environments independently while staying within enterprise guardrails. This self-service model eliminates manual ticketing bottlenecks, accelerates product delivery, and ensures security policies are applied consistently across all environments.
Management in Cloud-Native & Kubernetes Environments
As technology infrastructure moves toward large-scale container orchestration, managing dynamic distributed networks presents new performance and optimization challenges. Modern systems rely on advanced service mesh layers to encrypt inter-service traffic, enforce routing policies, and collect deep telemetric traces automatically. Teams face the challenge of managing highly dynamic, ephemeral container workloads that scale up and down instantly across multiple cloud regions. Overcoming these complexities requires building declarative automation engines that continuously audit cluster states and match resource usage to real-time application demands.
Operational Skills That Will Matter Most
The role of the operations engineer is evolving to require a balance of technical automation skills, data analysis capabilities, and financial efficiency focus. Modern infrastructure professionals must look past basic hardware alerts to analyze long-term system data trends and find deep performance bottlenecks (Güemes-Palau, 2026). With cloud budgets under close scrutiny, mastering cloud financial optimization—aligning resource performance to actual user load to eliminate waste—is a critical skill. Engineers who combine deep observability expertise with a proactive focus on cost-efficient, resilient architecture will lead the next generation of platform engineering.
FAQ Section
- What is the standard career path for an infrastructure operations engineer?Professionals typically enter the field as junior system administrators or support technicians, focusing on localized troubleshooting and basic server provisioning. With experience, they move into operations roles, where they build automated delivery pipelines and design infrastructure using code templates. Senior professionals advance into infrastructure architecture positions, where they design resilient, multi-region cloud environments and align engineering metrics with corporate goals.
- How does this discipline differ from traditional IT operations roles?Traditional IT management focuses on manually maintaining and patching specific physical servers and local network hardware. In contrast, modern infrastructure engineering treats the entire operational environment as programmable software. Operations engineers spend their time writing automation code, building self-healing systems, and scaling environments programmatically, eliminating the need for manual, box-by-box box interventions.
- What are the current global salary trends for reliability specialists?The high demand for stable, scalable enterprise systems keeps compensation levels strong for qualified engineering professionals globally. Mid-level operations engineers command premium salaries within major technology hubs, with compensation rising significantly for senior platform architects. Total compensation packages often include performance bonuses and equity options, reflecting the critical business value of maintaining system uptime.
- Why are error budgets considered essential for managing release risk?An error budget provides an objective, data-driven guardrail that balances product delivery speed with baseline system stability. It provides clear guidance on when development teams can safely roll out high-risk features or when they must pivot to fix infrastructure bugs. Using a clear metric removes organizational friction between feature developers and stability engineers, ensuring the platform remains reliable for users.
- Which scripting languages are most important for infrastructure automation?Python and Go are the primary languages used to build modern infrastructure automation and manage telemetry integrations. Python is widely used for creating deployment scripts, manipulating log data, and managing cloud provider APIs. Go has become the standard language for building modern cloud-native tools like Kubernetes and Terraform, making it essential for senior engineering roles.
- How do organizations calculate and track manual toil accurately?Teams track manual toil by keeping close logs of repetitive administrative tasks that offer no long-term structural improvement. Engineers measure how much time they spend on manual reboots, user access resets, and routine server updates. If these manual tasks consume more than half of the team’s engineering capacity, leadership steps in to prioritize automation work and clear the operational bottleneck.
Final Summary
Maintaining long-term systems health requires building integrated, observable architectures that replace manual intervention with code-driven automation. Modern enterprises achieve high reliability by setting clear, customer-aligned SLOs and systematically eliminating manual toil from their deployment pipelines. Treating operational incidents as opportunities for systemic improvement helps organizations build resilient platforms capable of handling massive scale variations. As technology infrastructure continues to shift toward complex, cloud-native container environments, the ability to build self-healing platforms remains a foundational competitive advantage.
The future of technology infrastructure belongs to organizations that integrate human operational engineering culture with advanced automation tools. Technical professionals who master infrastructure automation, deep telemetry, and cost-efficient design are positioned to lead these major enterprise transformations. Investing in hands-on, expert-led training programs allows engineers to develop the practical capabilities needed to manage high-traffic systems. Explore the comprehensive training programs and career tracks available at Noopsschool to build the specialized systems expertise required to run the next generation of digital platforms.